[re:Invent23] Knowledge bases for Amazon Bedrock
쉽고 경제적인 RAG 구축을 위한 Knowledge Bases for Amazon Bedrock 안내서
LLM이 질문에 대한 답변을 생성하는 과정에서 사실과는 다른 환각 현상이 발생할 수 있습니다. 환각을 최소화하기 위해 RAG(Retrieval Augmented Generation)라는 방법이 Meta에 의해 도입되었는데요. LLM이 입력을 받으면 특정 소스에서 관련한 문서를 찾아 context에 추가하고, 해당 정보를 토대로 최종 출력을 반환하게 되는 구조입니다. RAG를 통해서 Fine-Tuning을 하지 않고도 제한적인 정보를 가지고 있는 LLM을 보다 정확하고 커스텀하게 개선할 수 있게 되었습니다.
이러한 RAG의 단점이라면 아무래도 벡터 데이터베이스와 LLM과의 연동을 위하여 LangChain을 활용한 개발 공수가 수반된다는 것입니다. AWS는 CSP 중에서도 빠르게 이러한 RAG를 간소화하고 추상화한 서비스인 Knowledge bases for Amazon Bedrock를 re:Invent 2023에서 GA로 발표하였습니다.
이번 포스팅에서는 Knowledge bases의 각 옵션에 따른 차이와 구성 방법에 대해 공유하려 합니다.
Knowledge bases for Amazon Bedrock의 벡터 데이터베이스
2024년 1월 7일 기준, 총 4가지의 옵션을 제공하고 있습니다.
- Amazon OpenSearch Serverless
- Amazon Aurora
- Pinecone
- Redis Enterprise Cloud
2023년 12월 21일에 벡터 데이터베이스 종류로 Amazon Aurora가 추가되었습니다. Pinecone과 Redis Enterprise Cloud의 경우 AWS Native 서비스가 아니며 추가적인 관리 포인트를 요하기 때문에 본 포스팅에서는 논외로 하겠습니다.
따라서 AWS Native로 RAG를 구축하려면 Amazon OpenSearch Serverless 혹은 Amazon Aurora를 사용하게 되는데요. 여기서 Aurora Serverless는 콘솔 상에 명시되어 있지 않지만 Amazon Aurora를 선택하여 연동이 가능하며, 실제 운영 시에도 애플리케이션 상황에 따라 자동으로 확장/축소되어 관리가 줄어들기에 Aurora Serverless를 사용하기를 권장드립니다.
아무것도 없는 상태에서 새로 구축한다면 가장 편리한 것은 Amazon OpenSearch Serverless입니다. 아래와 같이 추가적인 정보 기입 없이 Knowledge base를 생성할 수 있습니다.
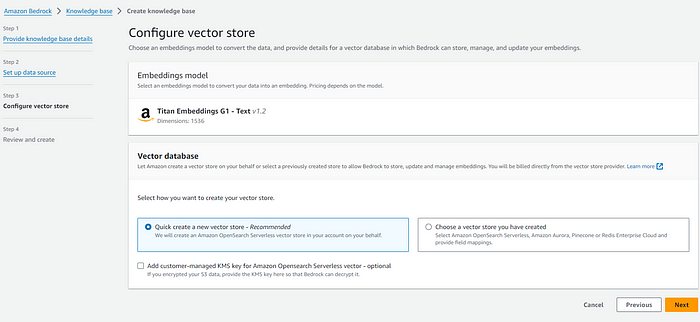
기존에 소유하고 있던 벡터 데이터베이스를 연동할 수도 있습니다. 이 경우에 OpenSearch Serverless도 가능하지만, 테스트 용도 혹은 문서가 많지 않거나 비용을 가장 낮게 사용하려면 Amazon Aurora Serverless (v2)를 권장하고 있습니다.
OpenSearch Serverless의 경우 비용이 부과되는 최소 단위인 OCU(OpenSearch Compute Unit)에 대해 알아야 하는데, 기본적으로는 최소 OCU가 4개입니다. 프로비저닝 시에 Indexing을 위한 OCU 2개, Search를 위한 OCU 2개가 생성됩니다. 개발/테스트 모드로 설정하여 Replica를 비활성화하면, 최소 OCU는 2개가 됩니다. 북미 버지니아 리전 기준 OCU당 비용이 시간당 $0.24 가 부과되며, 한 달이면 $0.24 * 2 * 24 * 30.5 = $351.36 가 부과됩니다.
Amazon Aurora Serverless는 최소 데이터베이스 구성 용량이 0.5 ACU(Aurora Capacity Unit)입니다. 버지니아 리전 기준 ACU당 비용이 시간당 $0.12 가 부과되며, 한 달이면 $0.12 / 2 * 24 * 30.5 = $43.92 로 OpenSearch Serverless 옵션에 비해 8배나 저렴한 옵션입니다.
Amazon Aurora Serverless로 Knowledge Base 구축하기
경제적으로 Knowledge Base를 구축할 수 있는 Amazon Aurora Serverless를 이용한 가이드를 공유해 보겠습니다.
가장 먼저 Aurora Serverless 인스턴스를 프로비저닝해야 합니다. 아래 버전 이상의 PostgreSQL DB 클러스터가 필요합니다.
- 15.4 이후 버전
- 14.9 이후 버전
- 13.12 이후 버전
- 12.16 이후 버전
추가적으로 pgvector 확장 기능 버전이 0.5.0 이상이어야 하며, Data API가 활성화, Secret Manager를 통해 관리되는 user 연결이 필수적인 조건입니다.
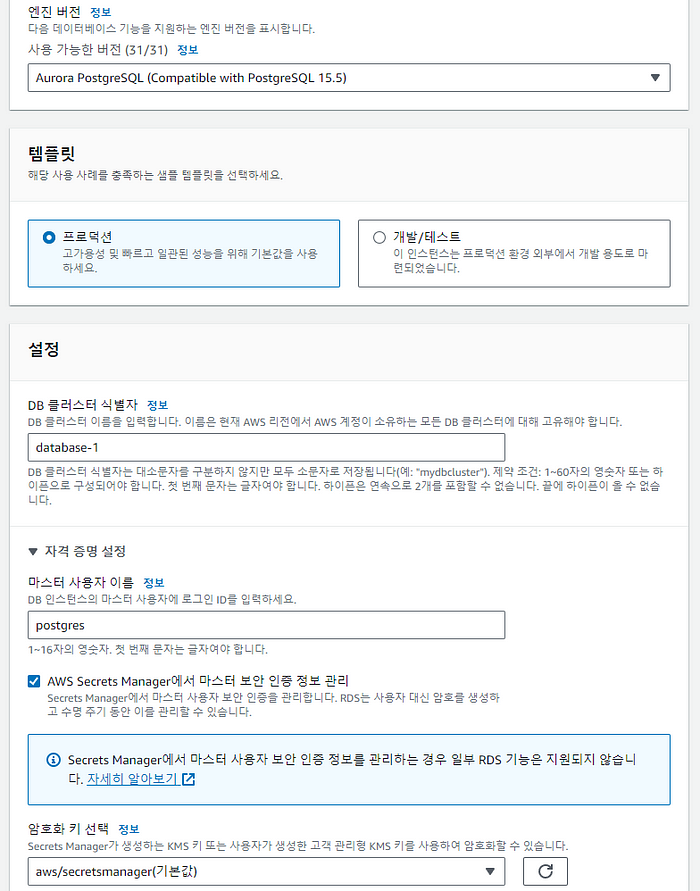
조건에 따라서 15.5 버전의 PostgreSQL 엔진 버전과, Secret Manager에서 User 정보를 관리하는 옵션으로 설정하였습니다.
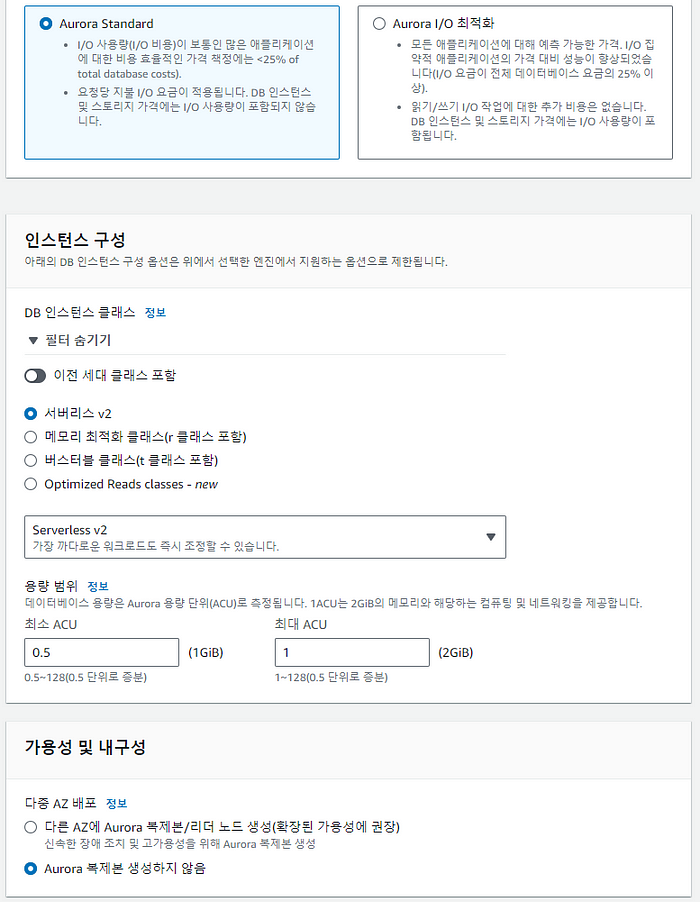
Serverless v2를 선택하고, ACU 최소 단위인 0.5 ACU로 동작하기 위해서 용량 범위를 0.5~1로 설정해 주고, 테스트 용도로 구성할 것이므로 복제본도 생성하지 않습니다.
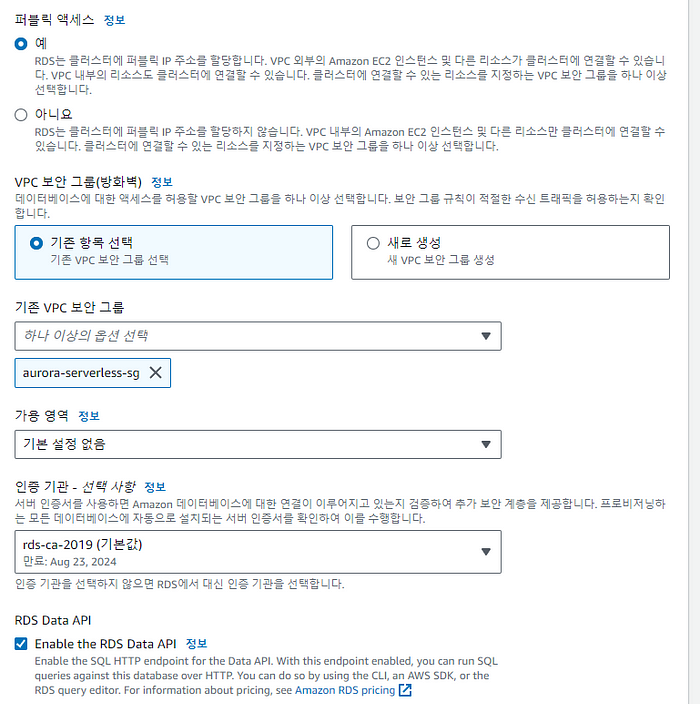
Knowledge Bases에서 접근하기 위해서 퍼블릭 액세스가 활성화되어 있어야 하며, 연결된 보안 그룹은 인바운드로 443 포트가 열려 있어야 합니다. 필수 조건 중 하나인 Data API를 활성화하는 것을 잊지 않아야 합니다. 이외의 옵션은 모두 Default로 설정해도 무관합니다.
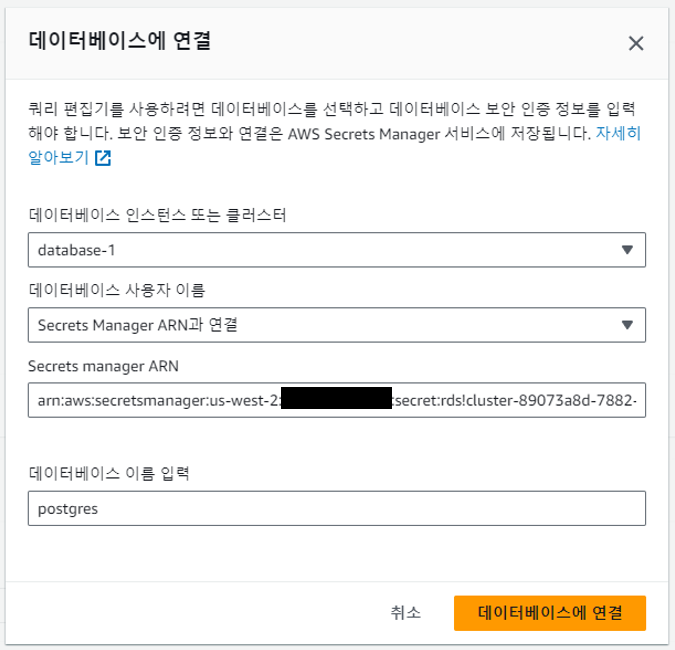
쿼리 편집기를 통해서 데이터베이스에 연결하여 pgvector 등 추가 설정을 완료해야 합니다. Secret Manager를 통해서 연결하며 DB 생성 시 입력한 마스터 사용자 이름으로 연결합니다. 아래 쿼리로 pgvector를 설치하며, 조건에 따라 0.5.0 이상으로 설치되었는지 확인해야 합니다.
CREATE EXTENSION IF NOT EXISTS vector;
SELECT extversion FROM pg_extension WHERE extname=‘vector’;
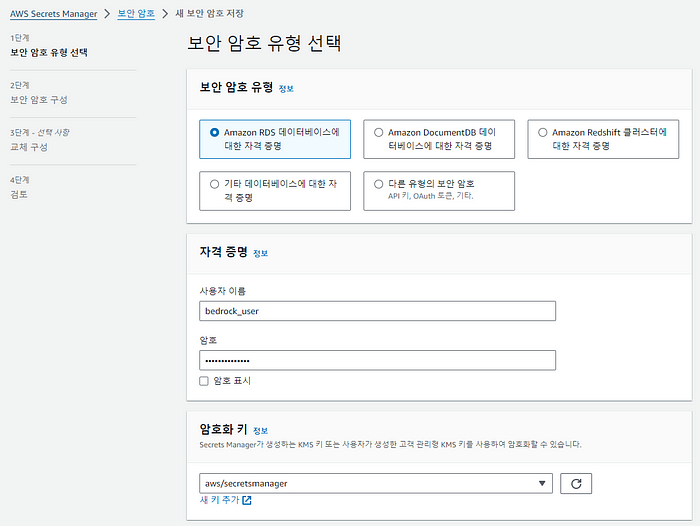
아래 쿼리를 통해 스키마, 롤을 생성하고 권한을 부여합니다. 해당 롤의 이름과 비밀번호는 Secret Manager에서 생성한 새로운 자격 증명과 일치해야 합니다.
CREATE SCHEMA bedrock_integration;
CREATE ROLE bedrock_user WITH PASSWORD ‘yourpassword’ LOGIN;
GRANT ALL ON SCHEMA bedrock_integration to bedrock_user;
다음 쿼리를 통해 bedrock과의 연동을 위한 테이블과 인덱스를 생성하면 Database에서의 설정은 모두 완료됩니다.
CREATE TABLE bedrock_integration.bedrock_kb (id uuid PRIMARY KEY, embedding vector(1536), chunks text, metadata json);
CREATE ALL ON bedrock_integration.bedrock_kb TO bedrock_user;
CREATE INDEX on bedrock_integration.bedrock_kb USING hnsw (embedding vector_cosine_ops);
Amazon Bedrock의 Knowledge Bases 콘솔로 진입합니다.
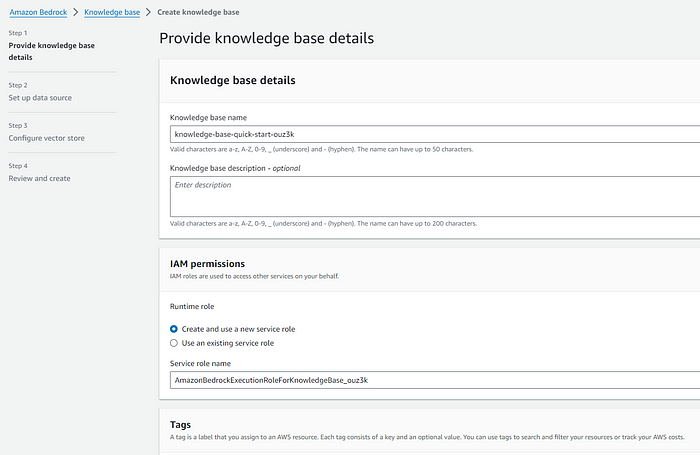
Knowledge Base 이름과 관련 권한을 설정합니다. 기본값으로 해도 무방합니다.
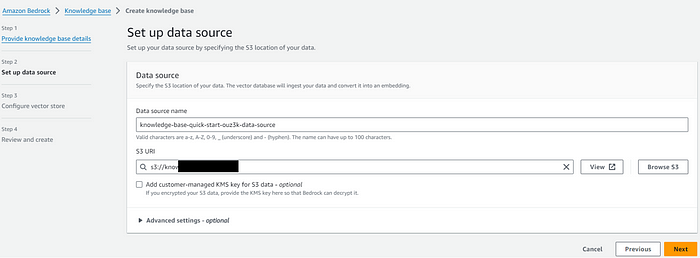
데이터 소스를 담고 있는 S3 버킷의 URI를 입력합니다. 해당 버킷에 담겨 있는 pdf, txt, xlsx, html, doc 등 파일 내 정보를 기반으로 LLM이 답변을 출력하게 됩니다.
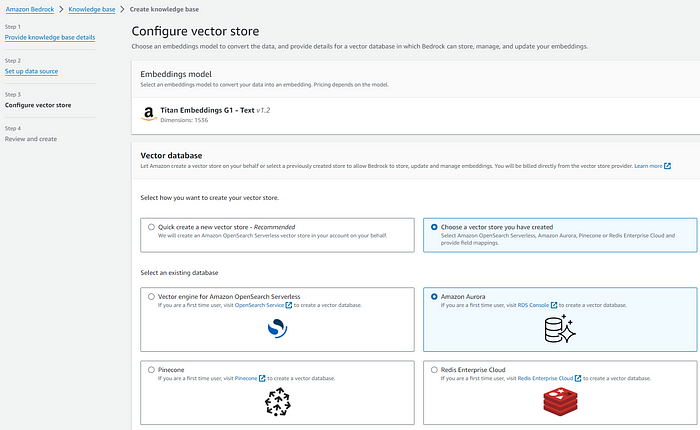
벡터 데이터베이스로 Amazon Aurora를 선택합니다. 참고로 S3 버킷 내 문서를 벡터화하는 엠베딩 모델은 Amazon의 Titan Embeddings를 사용하고 있으며, 보다 나은 한국어 엠베딩을 위해 KoSimCSE-roberta 등을 사용하길 원한다면 현재로서는 Knowledge Bases for Amazon Bedrock은 적합한 솔루션이 아닙니다.
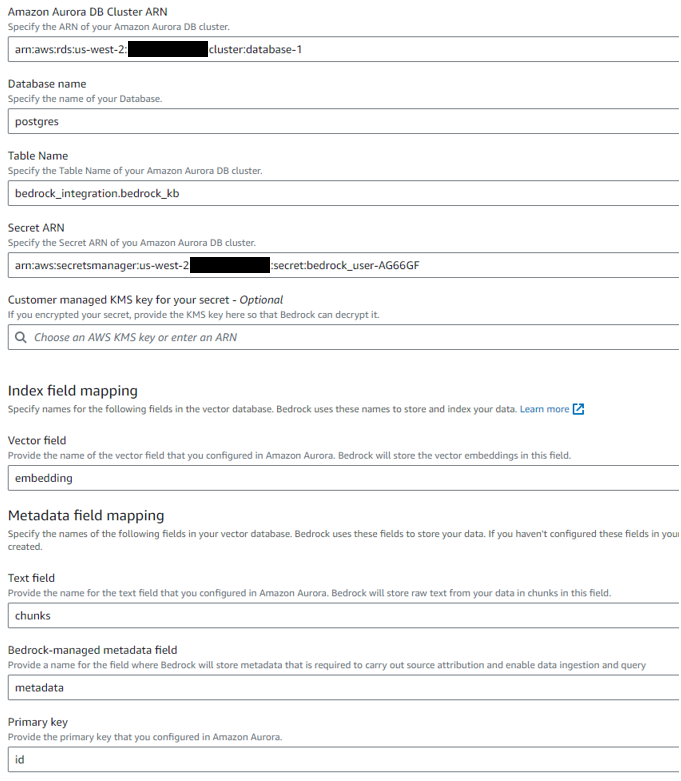
쿼리를 통해 입력한 정보와 매치되도록 모든 정보를 입력하여 생성을 완료합니다. Knowledge Base 생성 이후 Data Source 설정으로 이동하여 데이터 동기화를 위해 [Sync]를 눌러야 합니다.
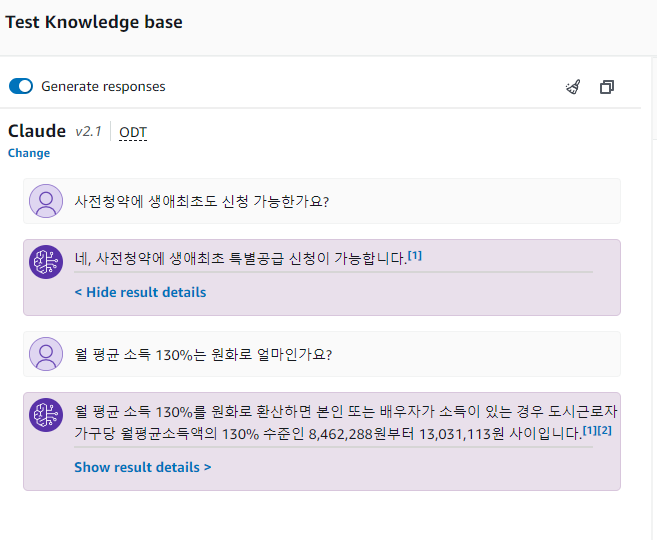
Knowledge Base 콘솔에서 위와 같이 간단하게 테스트 가능하며, 기존에 넣어놓은 소스 문서에서 관련한 부분을 찾아 context로 추가하여 최종 답변을 반환하는 것을 볼 수 있습니다. 쿼리 응답 시에는 참조한 context의 chunk를 같이 반환합니다.
Conclusion
권한 부여라든지 인덱스 필드 매핑이라든지 OpenSearch Serverless로 간단히 구성할 때에 비해 약간의 수고는 들지만 비용 효율적으로 Knowledge Base를 통해 보다 전문적이고 커스텀하게 답변을 생성하는 것을 확인할 수 있었습니다.
Knowledge Base는 re:Invent 2023에서 같이 출시된 Agents for Amazon Bedrock과 연계하여 내부 지식 기반뿐만 아니라 실시간 외부 지식 기반과 연동한 작업을 처리할 수도 있는 강력한 기능입니다. 앞으로도 더 많은 데이터베이스와 임베딩 모델이 추가되어 Gen AI 생태계를 더욱 확장할 수 있기를 기원합니다.
최신 댓글