지식그래프에 대한 RAG 구현하기
LLM은 환각 현상으로 인해 부정확한 정보를 생성하곤 합니다. RAG는 LLM의 응답 생성 과정 중 관련 문서를 검색하여 추가 컨텍스트를 제공함으로써 정확성을 높이도록 해왔습니다.
그러나 기존의 RAG 접근 방식은 주로 벡터 검색에 의존하여 복잡한 관계와 맥락을 충분히 반영하지 못하는 한계가 있었으며, 이런 배경에서 지식 그래프와 RAG를 결합한 GraphRAG가 주목받고 있습니다. GraphRAG는 단순한 키워드 매칭이나 벡터 유사도를 넘어, 데이터 간의 복잡한 관계와 맥락을 이해하고 보다 정확하고 맥락에 맞는 응답을 생성할 수 있게 도와주는 접근법입니다.
이번 포스팅에서는 Neo4j와 같은 그래프 데이터베이스를 활용한 지식 그래프 구축 방법, LangChain을 이용한 자연어 쿼리의 Cypher 변환 방법 등 실제 구현에 필요한 기술적 내용을 다루어 보려합니다.
GraphRAG
지식 그래프는 개체(Node)와 개체 간의 관계(Edge)를 그래프 구조로 표현한 데이터 모델입니다. GraphRAG는 이러한 지식 그래프의 특성을 활용해 여러 홉(hop)을 거치는 복잡한 관계도 추적하여 추론이 가능합니다. 예를 들어, “A 연구원과 협업한 연구원들이 주로 연구한 주제는 무엇인가?”와 같은 복잡한 질문에도 답변할 수 있게 됩니다.
또한, 응답 생성 과정에서 사용된 관계와 경로를 명확히 추적할 수 있어 결과의 설명이 용이한 장점이 있고, 이는 설명 가능한 LLM 애플리케이션을 설계할 때 가장 필요한 부분입니다.
기술 블로그 포스팅 데이터셋을 지식 그래프로 이해하기
추론을 위한 데이터셋을 구축하기 위해 Claude 3.5 Sonnet을 활용하여 가상의 기술 블로그 포스팅에 대한 정보를 명시한 합성 데이터를 아래와 같이 생성하였습니다.
| 제목;요약;주제;세부주제;작성자;발행일 Spring Boot 3.0의 새로운 기능;Spring Boot 3.0의 주요 변경사항과 새로운 기능을 소개하고, 이를 실제 프로젝트에 적용하는 방법을 설명합니다.;백엔드 개발;프레임워크;김철수,박영희;2023-05-12 딥러닝 모델 최적화 기법;TensorFlow를 사용한 딥러닝 모델의 성능 최적화 기법을 다루며, 실제 프로젝트에서의 적용 사례를 공유합니다.;머신러닝/AI;모델 최적화;이지훈,정미경;2023-07-23 React와 TypeScript를 활용한 효율적인 프론트엔드 개발;React와 TypeScript를 조합하여 안정적이고 유지보수가 용이한 프론트엔드 애플리케이션을 개발하는 방법을 소개합니다.;프론트엔드 개발;웹 프레임워크;홍길동,김민지;2023-09-04 마이크로서비스 아키텍처 설계 및 구현 사례;대규모 서비스의 마이크로서비스 아키텍처 전환 과정과 이를 통해 얻은 교훈을 공유합니다.;시스템 아키텍처;마이크로서비스;박성민,이지훈,정미경;2023-11-18 Kotlin Coroutines를 이용한 비동기 프로그래밍;Kotlin Coroutines의 기본 개념부터 실제 안드로이드 앱 개발에서의 활용 방법까지 상세히 설명합니다.;모바일 개발;안드로이드;최유진,김철수;2024-01-07 DevOps 파이프라인 구축: Jenkins와 Docker 활용;Jenkins와 Docker를 이용한 효율적인 CI/CD 파이프라인 구축 방법과 자동화 전략을 소개합니다.;DevOps;CI/CD;이상훈,박영희,홍길동;2024-02-22 GraphQL API 설계 및 성능 최적화;REST에서 GraphQL로의 전환 과정과 이에 따른 API 성능 최적화 기법을 다룹니다.;백엔드 개발;API 설계;정미경,이지훈;2023-08-15 웹 접근성 향상을 위한 프론트엔드 개발 기법;웹 애플리케이션의 접근성을 높이기 위한 HTML, CSS, JavaScript 활용 방법을 설명합니다.;프론트엔드 개발;웹 접근성;김민지,최유진;2023-10-30 대규모 데이터 처리를 위한 Apache Kafka 활용;Apache Kafka를 이용한 실시간 대용량 데이터 처리 시스템 구축 경험을 공유합니다.;빅데이터;데이터 스트리밍;박성민,김철수;2024-03-09 머신러닝 모델의 실시간 서빙 아키텍처;TensorFlow Serving을 이용한 머신러닝 모델의 효율적인 실시간 서빙 방법을 소개합니다.;머신러닝/AI;모델 서빙;이지훈,정미경,박영희;2023-12-05 Kubernetes를 활용한 마이크로서비스 운영;Kubernetes 기반의 마이크로서비스 배포 및 운영 전략과 모니터링 방법을 다룹니다.;클라우드;컨테이너 오케스트레이션;최유진,홍길동;2024-04-17 블록체인 기반 분산 애플리케이션 개발;이더리움 기반의 스마트 컨트랙트 개발과 웹3 애플리케이션 구현 방법을 설명합니다.;블록체인;dApp 개발;김철수,박성민,이상훈;2023-06-28 Flutter를 이용한 크로스 플랫폼 앱 개발;Flutter 프레임워크를 사용하여 iOS와 Android 플랫폼을 동시에 지원하는 앱을 개발하는 방법을 소개합니다.;모바일 개발;크로스 플랫폼;이지훈,김민지;2024-01-25 보안을 고려한 REST API 설계와 구현;안전한 REST API 설계 원칙과 OAuth 2.0을 이용한 인증 구현 방법을 다룹니다.;백엔드 개발;API 보안;정미경,최유진;2023-09-19 Vue.js 3.0과 Composition API 활용;Vue.js 3.0의 새로운 기능과 Composition API를 활용한 효율적인 컴포넌트 설계 방법을 설명합니다.;프론트엔드 개발;웹 프레임워크;박영희,이상훈,김철수;2024-03-30 NoSQL 데이터베이스 선택 가이드;다양한 NoSQL 데이터베이스의 특징을 비교하고 적절한 사용 사례를 소개합니다.;데이터베이스;NoSQL;홍길동,이지훈;2023-11-02 서버리스 아키텍처와 AWS Lambda 활용;AWS Lambda를 이용한 서버리스 애플리케이션 개발과 운영 경험을 공유합니다.;클라우드;서버리스;정미경,최유진,박성민;2024-02-14 TDD를 통한 견고한 백엔드 애플리케이션 개발;테스트 주도 개발(TDD) 방법론을 백엔드 개발에 적용하는 과정과 이점을 설명합니다.;백엔드 개발;테스팅;김민지,이상훈;2023-07-09 ElasticSearch를 활용한 검색 엔진 구축;ElasticSearch를 이용한 효율적인 전문 검색 시스템 구축 방법과 최적화 기법을 소개합니다.;데이터베이스;검색 엔진;최유진,이지훈;2024 |
아래 명령어를 통해 필요한 LangChain 등 필요한 라이브러리를 설치합니다.
%pip install neo4j langchain langchain-community python-dotenv langchain-aws
|
Neo4j 인스턴스 설정
오픈 소스 그래프 데이터베이스 관리 시스템인 Neo4j를 사용하여 지식 그래프를 생성합니다. 여기서는 무료로 사용 가능한 Neo4j Aura를 활용하여 진행하겠습니다. `.env` 파일을 사용하여 `NEO4J_URI`, `NEO4J_USERNAME`, 및 `NEO4J_PASSWORD`를 환경 변수로 설정 가능합니다.
import dotenv
dotenv.load_dotenv('.env', override=True)
import os
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(
url=os.environ['NEO4J_URI'],
username=os.environ['NEO4J_USERNAME'],
password=os.environ['NEO4J_PASSWORD'],
)
|
합성 데이터셋을 그래프로 로딩
아래 코드를 통해 블로그 포스트와 작성자로 구성된 합성 데이터를 Neo4j 데이터베이스에 로딩하였습니다.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
q_load_articles = """
LOAD CSV WITH HEADERS
FROM 'https://raw.githubusercontent.com/nuatmochoi/genai/refs/heads/main/synthetic_data.csv'
AS 행
FIELDTERMINATOR ';'
MERGE (a:블로그포스트 {제목:행.제목})
SET a.요약 = 행.요약,
a.발행일 = date(행.발행일)
FOREACH (작성자 in split(행.작성자, ',') |
MERGE (p:개발자 {이름:trim(작성자)})
MERGE (p)-[:작성하다]->(a))
FOREACH (주제 in [행.주제] |
MERGE (t:주제 {이름:trim(주제)})
MERGE (a)-[:주제이다]->(t))
FOREACH (세부주제 in [행.세부주제] |
MERGE (st:세부주제 {이름:trim(세부주제)})
MERGE (a)-[:세부주제이다]->(st))
"""
graph.query(q_load_articles)
graph.refresh_schema()
print(graph.get_schema)
|
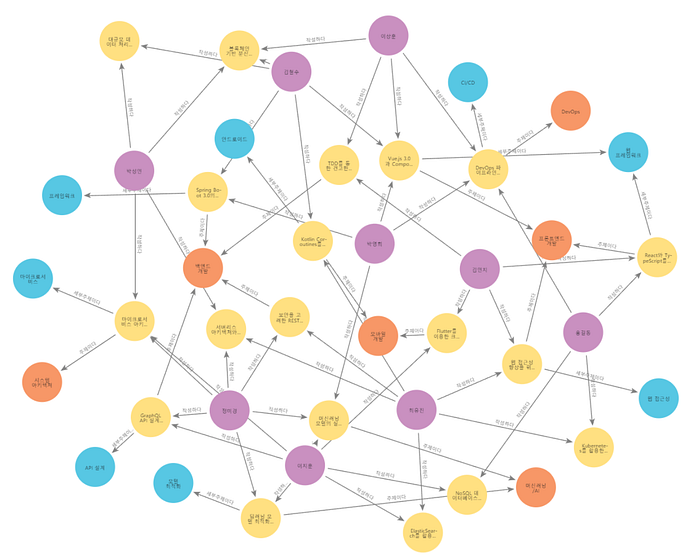
그래프 스키마 출력을 통해 그래프에 존재하는 개체와 그 관계를 아래와 같이 확인할 수 있습니다.

생성한 지식 그래프에 대한 시각화는 Neo4j Workspace에서 확인할 수 있습니다.
LangChain을 활용한 그래프 Cypher 체인 구성
LangChain에서 제공하는 GraphCypherQAChain을 통해 사용자의 자연어 기반 질문을 그래프 데이터 조회 언어인 Cypher로 변환할 수 있습니다. Amazon Bedrock 내 Claude 모델을 통해 추론하기 때문에 SageMaker 등 AWS 환경에서 호출하는 것이 아니라면 AWS 자격 증명에 대한 환경 변수 설정이 필요할 수 있습니다.
from langchain.chains import GraphCypherQAChain
from langchain_aws import ChatBedrock
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatBedrock(model_id="anthropic.claude-3-5-sonnet-20240620-v1:0"),
qa_llm = ChatBedrock(model_id="anthropic.claude-3-5-sonnet-20240620-v1:0"),
graph=graph,
verbose=True,
allow_dangerous_requests=True
)
|
자연어를 통한 쿼리 예시
블로그 포스팅 및 작성자로 이루어진 합성 데이터셋에 대해 이해하기 위해 3개의 질문을 아래와 같이 수행하였습니다.
# Example 1
cypher_chain.invoke(
{"query": "이지훈이 발표한 블로그는 총 몇 편인가요?"}
)
|
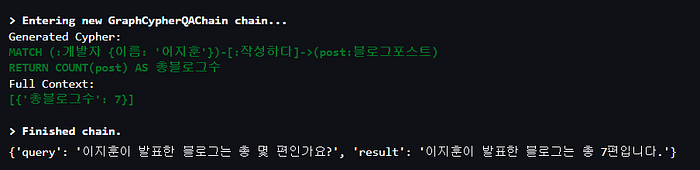
이름이 ‘이지훈’인 ‘개발자’ 노드를 매칭하고, ‘작성하다’ 관계를 통해 연결된 ‘블로그 포스트’ 노드를 찾아 개수를 카운트하는 Cypher 쿼리로 변환된 것을 확인할 수 있습니다.
# Example 2
cypher_chain.invoke(
{"query": "관심사가 같은 사람끼리 커피챗을 짝지어주려 합니다. 모든 사람이 포함되도록 그룹을 짝지어주세요."}
)
|
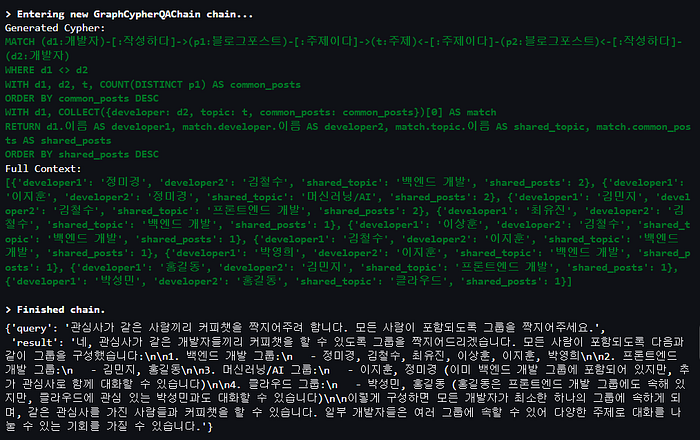
같은 주제로 작성한 ‘블로그 포스트’의 수를 계산하고, 가장 많은 공통 포스트를 가진 ‘개발자’ 쌍을 식별하도록 하는 쿼리로 변환되었습니다.
# Example 3
cypher_chain.invoke(
{"query": "가장 많은 동료와 함께 블로그를 작성한 사람은 누구인가요?"}
)
|

마지막 예시에서는 모든 ‘개발자’ 노드에서 시작하여 ‘작성하다’ 관계로 연결된 ‘블로그 포스트’를 찾고, 다시 역으로 동일한 ‘블로그 포스트’를 작성한 ‘개발자’를 찾는 쿼리를 수행하는 것을 확인할 수 있었습니다.
Conclusion
이번 포스팅에서는 GraphRAG의 개념과 그 구현 방법에 대해 간단히 살펴보았습니다. 복잡한 관계 추론이 필요한 질문에서 GraphRAG가 어떻게 더 정확하고 맥락에 맞는 답변을 제공하는지 예시를 통해 확인하였습니다.
본 글에서는 스키마를 직접 작성하는 방식을 사용하였으나 실제 프로덕션 환경에서는 이 과정을 자동화할 수 있습니다. 예를 들어, LlamaIndex의 PropertyGraphIndex와 같은 도구를 활용하면 LLM을 통해 스키마 작성까지 자동으로 수행할 수 있습니다.
GraphRAG는 복잡한 관계 정보를 다루는 다양한 분야에서 큰 잠재력을 가지고 있습니다. 학술 연구, 금융 분석, 추천 시스템, 뉴스 기사 검색 등에서 GraphRAG를 활용하여 단순한 정보 검색을 넘어 깊이 있는 인사이트를 제공할 수 있을 것으로 기대합니다.
최신 댓글