[re:Invent 2025] Amazon S3 Vectors: AI 시대를 위한 AWS의 첫 서버리스 대규모 벡터 스토리지
생성형 AI(Generative AI) 애플리케이션 구축에 있어 벡터 검색(Vector Search)과 RAG(검색 증강 생성)은 필수로 자리잡고 있습니다.
하지만 전용 벡터 데이터베이스를 구축하고 관리하는 것은 높은 비용과 복잡한 인프라 관리를 수반했습니다.
오늘 소개드릴 Amazon S3 Vectors는 이러한 고민을 해결해 줄 혁신적인 서비스입니다.
클라우드 오브젝트 스토리지인 S3가 이제 벡터 데이터를 네이티브로 저장하고 쿼리할 수 있게 되었습니다.
올해 정식 출시(General Availability)된 S3 Vectors의 핵심 기능과 업데이트 사항을 정리해 드립니다.
1. 벡터 데이터 활용성
생성형 AI(Generative AI) 시대가 열리면서, 기업이 보유한 데이터의 가치는 완전히 달라졌습니다.
하지만 아무리 방대한 데이터가 있어도, AI가 이를 이해하고 활용하지 못한다면 무용지물입니다.
AI 모델은 우리가 보는 텍스트, 이미지, 오디오와 같은 비정형 데이터를 원본 그대로 이해하지 못합니다.
이 문제를 해결하는 핵심 열쇠가 바로 벡터(Vector)와 임베딩(Embedding)입니다.
벡터화(임베딩)는 텍스트, 이미지, 오디오와 같은 비정형 데이터를 AI가 이해할 수 있는 수치화된 공간(벡터 공간)의 좌표로 변환하는 과정입니다.
단순히 숫자로 바꾸는 것이 아니라, 데이터가 가진 ‘의미(Semantics)’와 ‘문맥’을 숫자에 함축하는 것이 핵심입니다.
데이터 유형별 벡터 변환 (임베딩)
- 텍스트: 문장의 뉘앙스와 단어 간의 관계를 담은 텍스트 임베딩 (LLM 활용)
- 이미지: 픽셀 정보를 넘어 패턴, 스타일, 사물을 인식하는 이미지 임베딩 (ViT/CNN 활용)
- 오디오: 파형, 주파수, 목소리 톤을 분석한 오디오 임베딩
- 정형 데이터: 사용자 행동 로그나 구매 이력을 결합한 피처 벡터(Feature Vector)
이렇게 변환된 벡터 데이터는 단순한 저장 대상을 넘어, AI 애플리케이션의 핵심 엔진이 됩니다.
수억 개의 데이터 중에서 수학적 거리(유사도)가 가장 가까운 정보를 0.1초 만에 찾아낼 수 있기 때문입니다.
만들어진 고차원 벡터는 수학적 연산(코사인 유사도, 유클리드 거리 등)을 통해 데이터 간의 유사성과 의미적 관계를 파악하는 데 사용됩니다.
이를 바탕으로 우리는 AI에게 다음과 같은 강력한 능력을 부여할 수 있습니다.
- 맥락을 이해하는 검색 (Semantic Search): “겨울에 입기 좋은 따뜻한 옷”이라고 검색해도, 키워드가 일치하지 않는 ‘패딩’, ‘기모 후드’를 찾아냅니다.
- 환각 없는 답변 (RAG): AI가 학습하지 않은 최신 뉴스나 사내 비공개 문서를 실시간으로 참조하여 정확한 답변을 생성합니다.
- AI의 장기 기억 (Long-term Memory): 과거의 대화 내용이나 사용자 취향을 기억하여 개인화된 경험을 제공합니다.
그렇다면, 이렇게 중요한 벡터 데이터를 수십억, 수백억 개 규모로 늘어났을 때, 어떻게 효율적으로 저장하고 관리해야 할까요?
바로 벡터 DB를 활용하는 것 입니다.
2. S3 Vector란
Amazon S3 Vectors는 클라우드 오브젝트 스토리지 최초로 벡터 임베딩(Embeddings)을 기본적으로 저장하고 쿼리할 수 있는 기능을 제공합니다.
별도의 벡터 데이터베이스 인프라를 프로비저닝 할 필요 없이, S3의 내구성과 확장성을 그대로 활용하면서 AI 에이전트, 시맨틱 검색, RAG 등을 구현할 수 있습니다.
가장 큰 특징은 비용 효율성입니다. 기존 전문 벡터 데이터베이스 솔루션 대비 벡터 업로드, 저장, 쿼리 비용을 최대 90%까지 절감할 수 있습니다.
2.1 S3 Vector 성능
압도적인 확장성 (Scale)
- 단일 인덱스 당 20억 개 벡터 저장: 프리뷰(5천만 개) 대비 40배 증가했습니다. 이제 데이터를 여러 인덱스로 쪼개는 샤딩(Sharding)이나 복잡한 연합 쿼리 로직 없이 하나의 인덱스에서 대규모 데이터를 처리할 수 있습니다.
- 버킷 당 최대 20조 개 벡터: 단일 벡터 버킷에 최대 10,000개의 인덱스를 생성할 수 있습니다.
향상된 쿼리 및 쓰기 성능
- 지연 시간(Latency) 단축: 빈번한 쿼리의 경우 100ms(0.1초) 이하의 응답 속도를 제공하여 대화형 AI나 멀티 에이전트 워크플로우에 적합합니다. (비빈도 쿼리는 1초 이내)
- 쓰기 처리량 증가: 초당 1,000건의 PUT 트랜잭션을 지원하여, 실시간으로 유입되는 데이터를 즉시 검색 가능하게 만듭니다.
- 검색 결과 수 확대: 쿼리 당 최대 100개의 검색 결과(기존 30개)를 반환하여 RAG 애플리케이션에 더 풍부한 컨텍스트를 제공합니다.
2.2 주요 기능 및 작동 원리
벡터 버킷(Vector Buckets)과 인덱스
S3 Vectors는 새로운 버킷 타입인 ‘벡터 버킷’을 사용합니다.
이 안에 ‘벡터 인덱스’를 생성하여 데이터를 조직화하고 유사도 검색(Similarity Search)을 수행합니다.
거리 측정 알고리즘으로는 코사인(Cosine) 및 유클리드(Euclidean) 거리를 지원합니다.
메타데이터 필터링
벡터 데이터와 함께 메타데이터(Key-Value 쌍)를 저장할 수 있습니다.
- 필터링 가능 메타데이터: 카테고리, 날짜 등 검색 조건을 거는 용도로 사용.
- 필터링 불가능 메타데이터: 검색에는 쓰이지 않지만, RAG 구성 시 원문 텍스트 청크(Chunk) 등 컨텍스트 정보를 저장하는 용도로 활용 (최대 50개 키 저장 가능).
완전 관리형 서버리스 (Serverless)
인프라를 설정하거나 프로비저닝 할 필요가 없습니다. 사용한 만큼만 비용을 지불하며, 데이터가 늘어나거나 줄어듦에 따라 S3가 자동으로 최적화합니다.
2.3 강력한 통합 기능
S3 Vectors는 AWS의 AI/ML 생태계와 긴밀하게 연결되어 있습니다.
- Amazon Bedrock Knowledge Bases: S3 Vectors를 벡터 저장소 엔진으로 직접 선택하여 RAG 애플리케이션을 손쉽게 구축할 수 있습니다. (문서 파싱 -> 임베딩 생성 -> S3 Vectors 저장이 자동화됨)
- Amazon OpenSearch Service: 계층화된 스토리지 전략을 사용할 수 있습니다.
- 자주 조회되지 않는 대규모 콜드 데이터는 저렴한 S3 Vectors에 두고, 초저지연 검색이 필요한 핫 데이터는 OpenSearch로 이동시켜 비용과 성능의 균형을 맞출 수 있습니다.
- 보안 및 관리: AWS KMS를 통한 암호화, AWS PrivateLink를 통한 프라이빗 연결, CloudFormation을 통한 리소스 관리, 태그 기반 비용 관리를 모두 지원합니다.
2.4 S3 Vectors과 다른 벡터 DB의 차이점 (vs. pgvector, OpenSearch)
비용 구조의 혁신: “고비용 메모리 vs 저비용 오브젝트 스토리지”
- 기존 (pgvector/OpenSearch):
- 벡터 검색 속도를 위해 데이터를 고성능 메모리(RAM)나 고속 SSD(EBS)에 상주시켜야 합니다.
- 데이터가 수십억 건으로 늘어나면 스토리지 비용뿐만 아니라, 이를 지탱할 컴퓨팅 인스턴스 비용이 기하급수적으로 증가합니다.
- S3 Vectors:
- 데이터를 가장 저렴한 객체 스토리지인 S3에 저장합니다.
- 컴퓨팅과 스토리지가 완전히 분리되어 있어, 데이터 양이 늘어나도 비싼 DB 인스턴스를 증설할 필요가 없습니다.
- 전체 비용을 최대 90%까지 절감할 수 있습니다.
무한한 확장성과 운영 제로(Zero Ops)
- 기존 (pgvector/OpenSearch):
- 데이터가 늘어나면 샤딩(Sharding)을 고민해야 합니다.
- 인덱스를 쪼개고, 리밸런싱하고, 클러스터 용량을 증설하는 등 인프라 엔지니어링 리소스가 투입됩니다.
- S3 Vectors:
- 완전한 서버리스(Serverless)입니다.
- 사용자는 인덱스 용량이나 샤딩을 고민할 필요가 없습니다.
- 단일 인덱스에 20억 개, 버킷 하나에 20조 개의 벡터를 넣어도 S3가 알아서 처리합니다.
사용 목적 기반 벡터 DB 비교 테이블
| 비교 항목 | Amazon S3 Vectors | pgvector (RDS/Aurora) | Amazon OpenSearch |
|---|---|---|---|
| 주요 강점 | 압도적인 가성비 & 대용량 | 관계형 데이터와 결합 용이 | 초저지연 실시간 검색 & 정교한 쿼리 |
| 지연 시간 (Latency) | 수십 ms ~ 100ms (Warm) | 수 ms | 10ms 미만 (Hot) |
| 적합한 데이터 | 대규모 지식 베이스, 아카이브, RAG | 트랜잭션 데이터, 소규모~중규모 벡터 | 실시간 로그 분석, 쇼핑몰 검색 |
| 비용 | 매우 저렴 | 중간 | 높음 |
3. S3 Vector 사용 방법
3.1 S3 Vector 생성하기
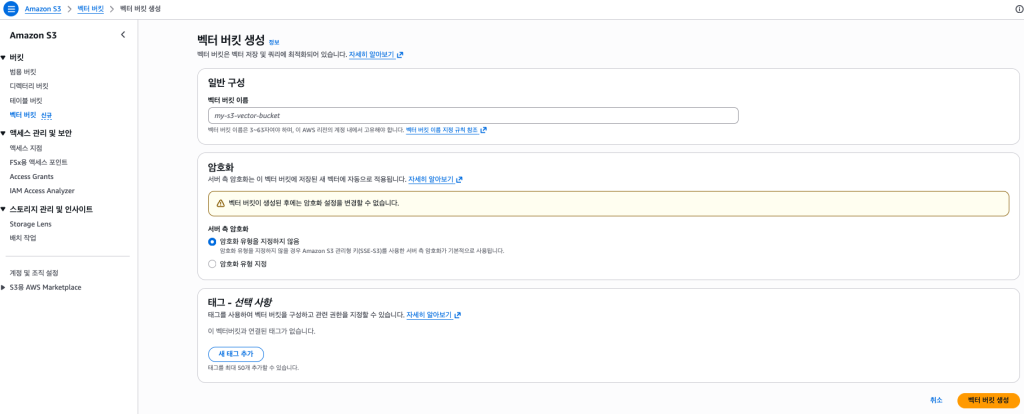
S3 벡터 버킷 생성
- 암호화 유형을 지정하지 않으면 Amazon S3는 새 벡터에 대해 Amazon S3 관리형 키(SSE-S3)를 사용한 서버 측 암호화를 기본 암호화 수준으로 적용합니다.
- 벡터 버킷 이름을 입력하고 암호화 유형을 선택합니다.
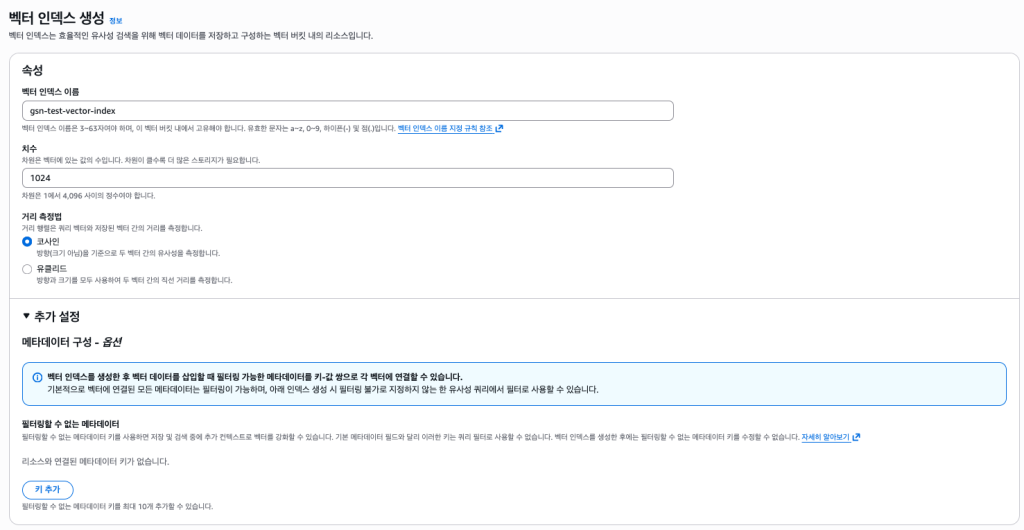
벡터 인덱스 생성
- 삽입할 벡터의 인덱스 이름과 차원을 입력합니다. 차원 메트릭은 벡터 계산에 사용된 모델의 차원과 일치해야 합니다.
- 거리 측정 방식 으로는 코사인 또는 유클리드 거리 를 선택합니다. 벡터 임베딩을 생성할 때는 보다 정확한 결과를 얻기 위해 임베딩 모델에서 권장하는 거리 측정 방식을 선택하는 것을 권장합니다.
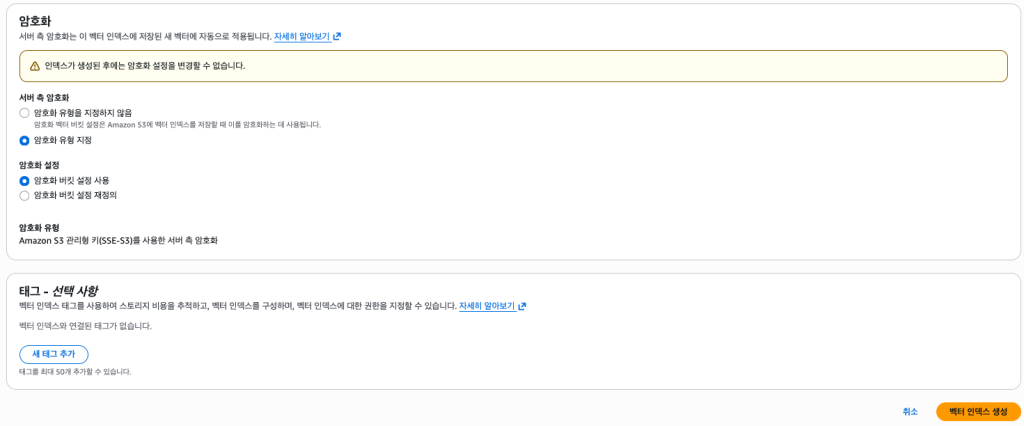
- 기본적으로 인덱스는 버킷 수준 암호화를 사용하지만, 버킷 수준 암호화를 재정의할 수 있습니다.
3.2 비정형 데이터에 대한 벡터 임베딩 생성하기
임베딩 모델 생성
벡터 임베딩을 벡터 인덱스에 삽입하려면 AWS 명령줄 인터페이스(AWS CLI) , AWS SDK 또는 Amazon S3 REST API를 사용할 수 있습니다 .
비정형 데이터에 대한 벡터 임베딩을 생성하려면 Amazon Bedrock에서 제공하는 임베딩 모델을 사용할 수 있습니다.
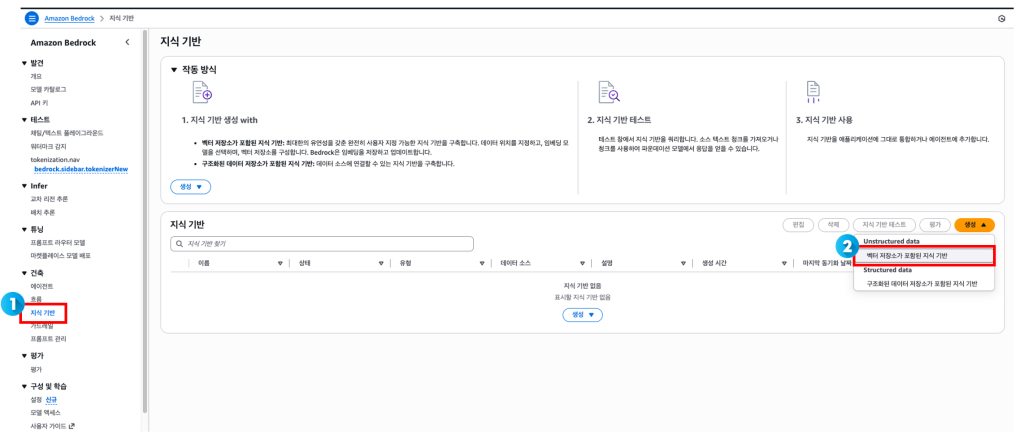
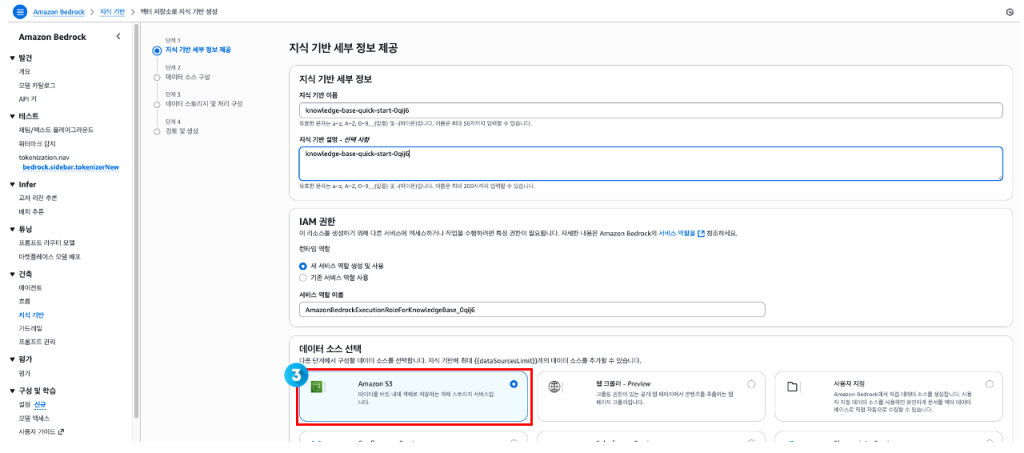
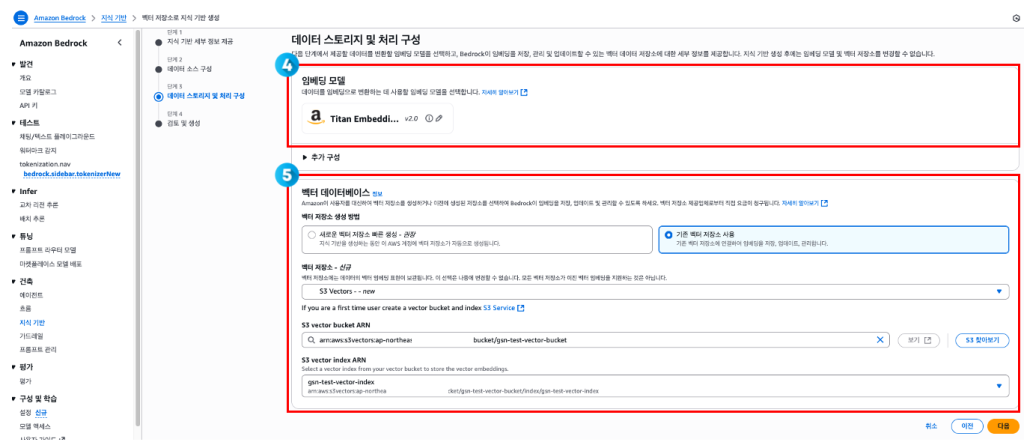
- 범용 S3 버킷에 저장된 PDF 문서를 가져오기 위해 Amazon Bedrock Knowledge Bases를 사용합니다.
- “벡터 저장소가 포함된 지식 기반”을 생성합니다.
- Amazon Bedrock Knowledge Bases는 문서를 읽어 청크라고 하는 여러 조각으로 나눕니다.
- 데이터를 임베딩으로 변환을 위해 사용할 임베딩 모델을 선택합니다.
- Amazon Titan Text Embeddings 모델을 사용하여 각 청크에 대한 임베딩을 계산하고, 벡터와 해당 메타데이터를 새로 생성된 벡터 버킷에 저장합니다.
이후 과정에 대한 자세한 단계는 이 글의 범위를 벗어나지만, 관련 문서에서 지침을 확인할 수 있습니다 .
벡터 인덱스에 벡터를 삽입하거나 벡터 목록을 조회, 쿼리 및 삭제하는 방법에 대한 자세한 내용은 Amazon S3 사용 설명서의 S3 벡터 버킷 및 S3 벡터 인덱스 섹션을 참조하세요.
자세한 내용은 S3 Vectors Embed CLI GitHub 저장소를 참조하세요.
4. 리전 및 가격 정책
4.1 이용 가능 리전
현재 서울(Seoul) 리전을 포함하여 전 세계 14개 AWS 리전에서 즉시 사용 가능합니다.
기존 프리뷰에서 제공되던 5개 리전(미국 동부(오하이오, 버지니아 북부), 미국 서부(오리건), 아시아 태평양(시드니), 유럽(프랑크푸르트))에 더해
아시아 태평양(뭄바이, 서울, 싱가포르, 도쿄), 캐나다(중부), 유럽(아일랜드, 런던, 파리, 스톡홀름)이 추가되었습니다.
4.2 가격 모델
S3 Vectors 가격은 다음 세 가지 요소로 구성됩니다.
- PUT 요금: 업로드한 벡터의 논리적 데이터 크기 기반
- 스토리지 요금: 인덱스 내 벡터의 총 논리적 저장량
- Query 요금
- API 호출당 요금
- 인덱스 크기(벡터 수)에 따라 TB 기반 요금 적용
- 100,000개 초과 벡터에 대해 GB 단위 가격 할인 적용
일반적인 벡터 DB 대비 최대 90% 저렴하게 운영할 수 있습니다.
5. 활용 분야
S3 Vectors는 사실상 모든 AI 기반 검색·추천·분석 시스템의 기반이 될 수 있습니다.
- 대규모 문서 기반 RAG 시스템
- AI Agents 장기 메모리 저장소
- 이미지·비디오·오디오 임베딩 저장
- 기업 전체 지식베이스 구축
- 고객 데이터 임베딩 저장/검색
- 보안 로그 유사도 분석
- 개인화 추천 엔진
- 멀티모달 AI 시스템
특히 벡터 데이터를 장기간 저장하는 대규모 기업에게 강력한 비용 절감 효과를 제공합니다.
6. 마치며
Amazon S3 Vectors는 “AI-ready Storage”라는 새로운 패러다임을 제시합니다.
저비용, 고확장성, 서버리스, 네이티브 벡터 쿼리까지 제공하여
전통적인 벡터 데이터베이스의 운영 부담과 비용 문제를 근본적으로 해결합니다.
이제 개발자들은 복잡한 벡터 DB 관리 부담에서 벗어나, S3에 파일을 올리듯 간편하고 저렴하게 수십억 건의 벡터 데이터를 처리할 수 있게 되었습니다.
대규모 RAG, 멀티에이전트, 온프레미스 데이터 AI 전환 등
기업 AI 프로젝트에서 가장 중요한 기반 스토리지로 자리잡을 가능성이 매우 높습니다.
지금 바로 AWS 콘솔에서 벡터 버킷을 생성하고, 여러분의 AI 애플리케이션에 무한한 기억력을 선물해 보세요.
최신 댓글