[re:Invent 2025] AWS Clean Rooms : Why – AWS Clean Rooms가 필요한 시대적 배경
데이터를 공유하지 않고도 협업할 수 있다면?

2025년 12월, 라스베이거스 베네치안 호텔에서 열린 AWS re:Invent. 5만 명이 넘는 개발자와 기업 의사결정자들이 모인 이 자리에서, AWS Clean Rooms의 새로운 기능들이 발표되었습니다. 단순한 서비스 업데이트 발표가 아니었습니다. 이는 데이터 협업의 패러다임이 근본적으로 변화하고 있음을 알리는 신호탄이었습니다.
Foursquare Business Development 부문 VP는 이렇게 말했습니다.
“당사자 간에 데이터를 이전하거나 복사하지 않고도 미디어 파트너의 광고 노출 데이터 및 당사의 오프라인 변환 데이터와 결합하여 제1자 데이터를 활용할 수 있는 개인 정보 보호 향상 메커니즘이 필요합니다. AWS Clean Rooms는 브랜드 고객과 고객의 미디어 파트너를 위해 AWS에서 데이터를 인플레이스 분석할 수 있도록 지원하는 혁신적인 솔루션입니다.”
이 시리즈는 AWS Clean Rooms가 무엇이고, 왜 필요하며, 어떻게 사용하고, 어디에 적용할 수 있는지를 다룹니다. 이번 글에서는 “왜 Clean Rooms인가?“라는 질문에 답하겠습니다.
1. re:Invent 2025와 데이터 협업 패러다임 변화
AI 시대, 데이터는 더 이상 혼자 가질 수 없다
생성형 AI가 등장한 이후, 모든 기업이 AI 도입에 열을 올리고 있습니다. 하지만 곧 벽에 부딪힙니다. 단일 조직이 보유한 데이터만으로는 충분하지 않다는 사실을 깨닫게 되는 것입니다.
광고 플랫폼을 운영하는 한 기업을 예로 들어보겠습니다. 이 회사는 연간 100억 달러의 광고비를 집행하지만, 정작 광고가 실제 구매로 이어졌는지는 정확히 알 수 없습니다. 광고주는 누가 구매했는지 알고, 미디어사는 누구에게 광고를 보여줬는지 압니다. 하지만 이 두 정보를 연결하지 못하면, 광고 효과는 추정치에 불과합니다. McKinsey의 2024년 보고서에 따르면, 이러한 데이터 단절로 인해 광고 예산의 30-40%가 비효율적으로 집행되고 있습니다.
의료 분야는 더 심각합니다. 희귀 질환 연구를 위해서는 충분한 환자 샘플이 필요합니다. 하지만 단일 병원에서는 환자 수가 턱없이 부족합니다. 병원 A에 23명, 병원 B에 31명, 병원 C에 18명의 환자가 있다면, 세 병원의 데이터를 합치면 72명입니다. 여전히 통계적 유의성을 확보하기에는 부족하지만, 적어도 연구를 시작할 수는 있습니다. 문제는 의료 데이터가 가장 민감한 개인정보라는 점입니다. 병원 간 데이터 공유는 사실상 불가능합니다.
금융 사기 탐지도 마찬가지입니다. 조직화된 금융 사기범들은 여러 금융기관을 넘나들며 활동합니다. 오전 9시에 A은행에서 100만원, 9시 15분에 B은행에서 150만원, 9시 30분에 C카드사에서 200만원을 인출합니다. 각 기관 입장에서는 모두 정상 범위의 거래입니다. 하지만 30분 내에 4개 기관에서 570만원이 이동했다면, 이는 명백한 사기 패턴입니다. 각 기관이 자사 데이터만 보고 판단하기 때문에, 사기 탐지 시스템이 이를 놓치고 맙니다.
Gartner는 2027년까지 Fortune 500 기업의 75%가 Clean Rooms 기술을 도입할 것으로 예측합니다. 데이터 협업 시장은 2025년 23억 달러에서 2030년 158억 달러로, 연평균 47% 성장할 것으로 전망됩니다. 이는 단순한 기술 트렌드가 아니라, 비즈니스 생존의 문제가 되고 있습니다.
개인정보 보호 규제, 이제는 생존의 문제
데이터 협업의 필요성이 커지는 동시에, 개인정보 보호 규제는 점점 더 강화되고 있습니다. 이는 단순한 법적 요구사항을 넘어, 기업의 생존과 직결된 문제가 되었습니다.
유럽의 GDPR은 2018년 시행 이후 가장 강력한 개인정보 보호 규제로 자리잡았습니다. 위반 시 최대 2천만 유로 또는 전 세계 연간 매출의 4% 중 높은 금액을 벌금으로 부과합니다. 2023년 한 해에만 24억 유로, 우리 돈으로 약 3조 5천억원의 벌금이 부과되었습니다. Meta는 2023년에 12억 유로, 약 1조 7천억원의 벌금을 냈습니다. 미국으로 사용자 데이터를 전송한 것이 문제였습니다. Amazon은 2021년에 7억 4천 6백만 유로, 약 1조원을 냈습니다. 타겟 광고를 위한 동의 절차가 불충분했기 때문입니다.
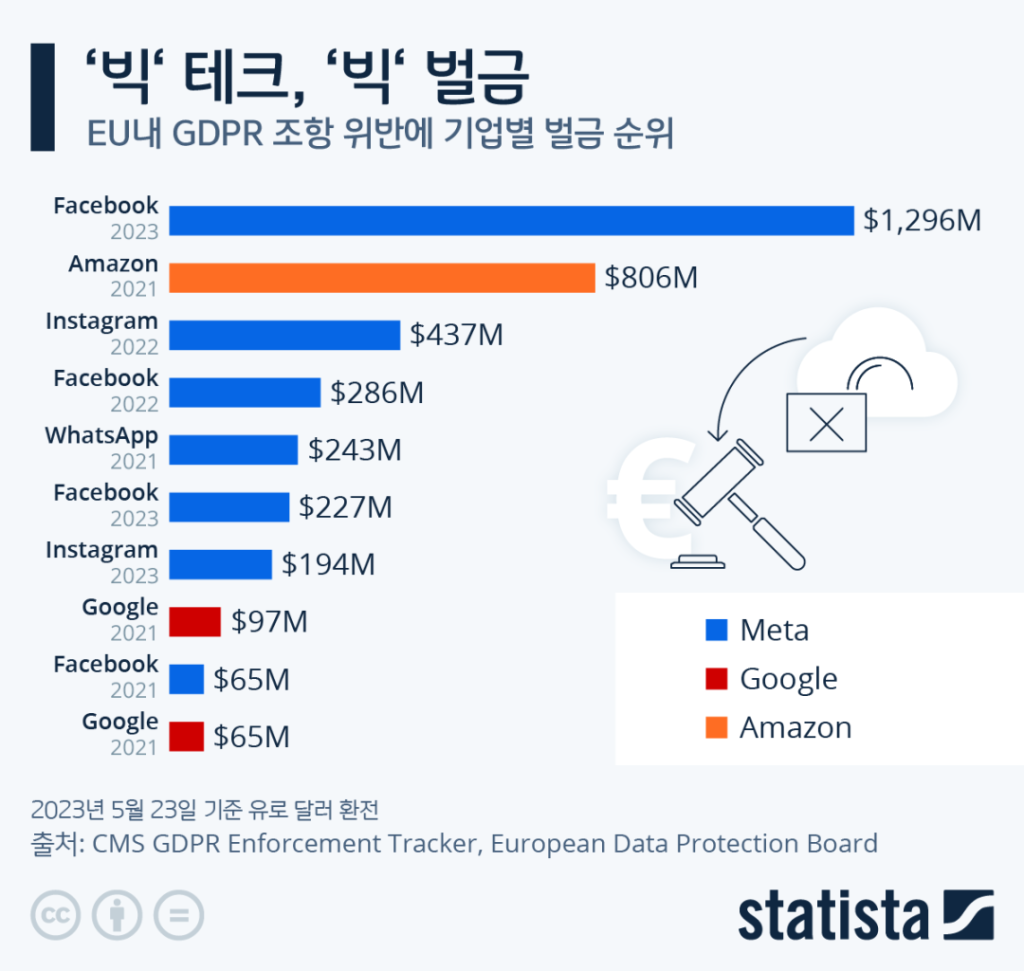
미국 캘리포니아의 CCPA와 CPRA도 만만치 않습니다. 소비자는 자신의 개인정보 판매를 거부할 수 있고, 삭제를 요청할 수 있으며, 기업은 이를 반드시 이행해야 합니다. 위반 시 건당 최대 7,500달러의 벌금이 부과되며, 집단 소송도 가능합니다. 화장품 리테일러 Sephora는 2022년에 120만 달러를 냈습니다. 개인정보를 판매하면서 이를 고객에게 알리지 않았기 때문입니다.
한국의 개인정보보호법도 2020년 전면 개정 이후 강력한 규제 체계를 갖추었습니다. 가명정보를 결합하려면 전문기관의 승인이 필요하고, 5만명 이상의 민감정보를 처리하면 개인정보 영향평가를 받아야 합니다. 위반 시 최대 5년 이하 징역 또는 5천만원 이하 벌금, 매출액의 3% 이하 과징금이 부과됩니다. 네이버는 2023년에 67억원, 쿠팡은 2022년에 30억원, 카카오는 2021년에 60억원의 과징금을 냈습니다.
IBM의 2024년 보고서에 따르면, 평균적인 데이터 유출 사고의 비용은 445만 달러, 약 60억원입니다. 규제 위반이 포함되면 590만 달러, 약 80억원으로 증가합니다. 하지만 진짜 문제는 벌금이 아닙니다. 브랜드 이미지 손상, 고객 이탈(평균 30-40%), 주가 하락(발표 후 1개월간 평균 -7.5%), 파트너사 신뢰 하락, 신규 비즈니스 기회 상실 등 간접 비용이 훨씬 큽니다.
“데이터를 공유해야 하지만, 공유하기 어렵다”
이제 기업들은 심각한 딜레마에 직면했습니다. AI와 데이터 분석을 위해서는 여러 조직의 데이터를 결합해야 합니다. 하지만 규제와 보안 리스크 때문에 실제로 데이터를 공유하기는 매우 어렵습니다.
2. 기존 데이터 공유 방식의 한계
기업들이 데이터 협업을 시도하지 않은 것은 아닙니다. 여러 방법을 시도했지만, 모두 근본적인 한계에 부딪혔습니다.
파일 기반 공유: 판도라의 상자를 여는 것
가장 오래되고 흔한 방법은 CSV나 Parquet 파일을 주고받는 것입니다. 간단해 보이지만, 이는 판도라의 상자를 여는 것과 같습니다.
파일을 전달하는 순간, 데이터에 대한 통제권을 완전히 상실합니다. 회사 A가 고객 데이터 파일(10GB)을 회사 B에게 이메일이나 FTP로 전송했다고 가정해봅시다. 이틀 후, 회사 B의 직원 5명이 이 파일을 다운로드합니다. 개인 PC에, 노트북에 복사본이 생깁니다. 일주일 후, 회사 B는 파트너사 C에게 일부 데이터를 재공유합니다. 회사 A는 이 사실조차 모릅니다. 한 달 후, 고객이 데이터 삭제를 요청합니다. 회사 B는 “삭제했습니다”라고 답하지만, 실제로는 백업에 남아있습니다. 회사 C는 삭제 요청조차 받지 못합니다. 3개월 후, 회사 B 직원의 노트북이 분실됩니다. 10GB의 고객 데이터가 유출되지만, 회사 A는 사고 발생 사실조차 모릅니다.

2019년 Capital One 데이터 유출 사건이 대표적입니다. 1억 600만 명의 고객 정보가 유출되었고, 신용카드 신청서와 사회보장번호가 포함되어 있었습니다. 파트너사와 공유한 데이터가 부적절하게 저장된 것이 원인이었습니다. 벌금 8천만 달러, 집단 소송 합의금 1억 9천만 달러, 주가 6% 하락으로 시가총액 30억 달러가 증발했습니다. 브랜드 이미지 손상은 금액으로 환산할 수 없습니다.
버전 관리도 악몽입니다. 첫 주에 customers_v1.csv(100만 건)를 보냅니다. 둘째 주에 데이터가 업데이트되어 customers_v2.csv(105만 건)를 다시 보냅니다. 파트너는 “v1으로 분석한 결과와 v2로 분석한 결과가 다릅니다”라고 합니다. 셋째 주에 긴급 수정이 필요해서 customers_v2_hotfix.csv를 보냅니다. 하지만 파트너는 이미 v2로 분석을 완료했습니다. 넷째 주에 파트너는 “우리 팀원 A는 v1, B는 v2, C는 v2_hotfix를 사용 중입니다. 어떤 버전이 정확한가요? 각 버전으로 분석한 결과가 모두 다릅니다”라고 합니다. 어떤 버전으로 분석했는지 추적할 수 없고, 분석 결과의 재현성도 없으며, 팀원 간 혼란만 가중됩니다.
보안 리스크도 심각합니다. 이메일 첨부는 평문으로 전송될 수 있고, FTP는 암호화되지 않은 프로토콜입니다. 클라우드 스토리지 공유 링크는 링크가 유출되면 누구나 접근할 수 있습니다. 파트너사의 보안 수준을 통제할 수 없고, 개인 PC에 저장 시 암호화 여부도 알 수 없습니다. Verizon의 2024 Data Breach Report에 따르면, 데이터 유출의 43%가 파일 공유 과정에서 발생하며, 평균 탐지 시간은 207일입니다. 유출 후 7개월이 지나서야 발견된다는 뜻입니다.
플랫폼 기반 공유: 복잡성의 늪
Redshift, Snowflake, BigQuery 같은 데이터 웨어하우스의 Cross-account sharing 기능은 파일 공유보다 낫지만, 여전히 한계가 있습니다.
권한 제어가 복잡합니다. 고객 테이블을 파트너와 공유한다고 가정해봅시다. 기본적으로 공유하면 파트너가 모든 컬럼을 볼 수 있습니다. 이메일, 전화번호 같은 민감한 컬럼도 노출됩니다. 이를 막으려면 뷰를 만들어야 합니다. 특정 컬럼만 포함하는 뷰를 만들고, 이 뷰를 공유합니다. 하지만 이는 정적입니다. 파트너가 원하는 분석을 할 수 없습니다. 새로운 요구사항이 생길 때마다 뷰를 추가해야 합니다.
파트너가 10개면 뷰도 10개가 필요합니다. 파트너 A는 전체 데이터, 파트너 B는 최근 1년 데이터만, 파트너 C는 특정 지역 데이터만 필요합니다. 각각 별도의 뷰를 만들어야 합니다. 유지보수는 악몽이 됩니다. 각 파트너의 요구사항이 변경될 때마다 뷰를 수정해야 합니다. Row-level security와 Column-level security를 설정할 수 있지만, 정책이 복잡해질수록 관리가 불가능해집니다. 실수로 과도한 권한을 부여할 수 있고, 감사 및 검증도 어렵습니다.
분석 유연성도 부족합니다. “우리 광고 캠페인의 효과를 다양한 각도로 분석하고 싶습니다. 연령대별, 지역별, 시간대별 전환율을 보고, 다양한 Attribution 모델을 비교하고, 코호트 분석을 하고, 실험적인 세그먼트 분석을 하고 싶습니다”라고 하는 예시를 상상해보겠습니다. 하지만 현실은 데이터 제공자가 미리 정의한 5개의 뷰만 사용 가능합니다. daily_conversions, weekly_conversions, monthly_conversions, region_summary, age_group_summary. 파트너가 “연령대와 지역을 동시에 분석하고 싶습니다”라고 하면, “새로운 뷰를 만들어드리겠습니다. 2주 소요됩니다”라고 답해야 합니다. “특정 제품 카테고리만 분석하고 싶습니다”라고 하면, “또 다른 뷰를 만들어드리겠습니다. 2주 소요됩니다”라고 답해야 합니다. “이번 주 프로모션 효과를 긴급 분석해야 합니다”라고 하면, “죄송하지만 뷰 생성에 최소 1주일 필요합니다”라고 답해야 합니다. 분석 속도가 저하되고, 비즈니스 기회를 상실하며, 파트너 불만이 증가하고, 제공자의 운영 부담도 증가합니다.
비용과 성능 문제도 있습니다. Snowflake Data Sharing는 공유 자체는 무료이지만, 파트너의 쿼리 실행 비용은 기본적으로 제공자가 부담합니다. 파트너가 비효율적인 쿼리를 실행하면 제공자의 비용이 폭증합니다. 파트너가 전체 테이블 스캔 쿼리를 반복 실행하고, 파티션 없이 대용량 JOIN을 수행한다면, 제공자는 비용 폭증 사실을 월말에 발견할 수 밖에 없습니다..
전통적 방법들의 공통된 문제
파일 공유든 플랫폼 공유든, 전통적인 방법들은 근본적인 한계를 공유합니다.
- 첫째, 데이터 복제입니다. 데이터를 복사하는 순간 통제권을 상실합니다.
- 둘째, 이분법적 선택입니다. “전부 공유” 또는 “전혀 공유 안 함” 중 하나를 선택해야 합니다.
- 셋째, 사후 보안입니다. 공유 후에 보안 조치를 취하지만, 이미 늦습니다.
- 넷째, 정적 권한입니다. 미리 정의된 접근 패턴만 가능하고, 유연성이 없습니다.
우리에게 필요한 것은 완전히 다른 접근 방식입니다.
- 데이터를 이동하지 않고도 협업할 수 있어야 합니다.
- 세밀한 권한 제어가 가능해야 합니다.
- 설계 단계부터 프라이버시를 보호해야 합니다.
- 유연한 분석과 보안의 균형을 맞춰야 합니다.
- 자동화된 규제 준수가 필요합니다.
이것이 바로 AWS Clean Rooms가 해결하려는 문제입니다.
3. Clean Rooms 개념 정의
전통적인 방식을 생각해봅시다. 회사 A의 데이터를 회사 B로 복사합니다. 회사 B가 분석합니다. 문제는 데이터 통제권을 상실한다는 것입니다. Clean Rooms 방식은 다릅니다. 회사 A의 데이터는 원래 위치에 그대로 유지됩니다. 회사 B의 데이터도 원래 위치에 그대로 유지됩니다. Clean Rooms은 양쪽 데이터를 “참조”하여 분석하고, 결과만 공유합니다. 데이터 통제권은 각자가 계속 유지합니다.
구체적으로 어떻게 작동할까요? 회사 A는 S3 버킷의 customers 테이블을 Clean Rooms에 “등록”합니다. 실제 데이터는 A의 S3에 그대로 있습니다. Clean Rooms은 메타데이터, 즉 스키마만 알게 됩니다. 회사 A는 권한을 설정합니다. “이 테이블로 집계 쿼리만 허용합니다. 최소 100명 이상일 때만 결과를 반환합니다. 이메일, 전화번호 컬럼은 접근 불가입니다.”
회사 B가 SQL 쿼리를 작성합니다. Clean Rooms은 먼저 권한 규칙을 검증합니다. 허용되지 않은 컬럼을 사용했다면 거부합니다. 집계 없이 개별 레코드를 조회하려 한다면 거부합니다. 검증을 통과하면, Athena가 A의 S3에서 직접 데이터를 읽어 쿼리를 실행합니다. 결과에 프라이버시 규칙을 적용합니다. 100명 미만의 그룹은 제거합니다. 필요하면 노이즈를 추가합니다. 최종 결과만 B에게 반환합니다.
회사 A는 언제든지 공유를 중단할 수 있습니다. 모든 쿼리 로그를 확인할 수 있습니다. 데이터를 업데이트하면 자동으로 반영됩니다. B는 항상 최신 데이터를 분석합니다. 중간 복사본은 생성되지 않습니다. 보안 리스크가 최소화됩니다.
광고 Attribution 를 상상해보겠습니다. 광고주는 구매 데이터를 가지고 있습니다. customer_id, purchase_date, amount, product. 미디어사는 광고 노출 데이터를 가지고 있습니다. user_id, exposure_date, campaign_id, ad_id. 각자의 S3에 저장되어 있습니다. Clean Rooms에서 쿼리를 실행합니다. 두 테이블을 customer_id와 user_id로 조인합니다. 광고 노출 후 7일 이내 구매를 찾습니다. 캠페인별로 집계합니다. 100명 이상인 그룹만 반환합니다. 결과는 campaign_id, converters, revenue입니다. 개별 고객 정보는 노출되지 않습니다. 광고주의 데이터는 광고주의 S3에 그대로 있습니다. 미디어사의 데이터는 미디어사의 S3에 그대로 있습니다.
Multi-party Secure Collaboration
Clean Rooms은 2개 이상의 조직이 안전하게 협업할 수 있는 환경을 제공합니다. 역할이 명확히 정의됩니다.
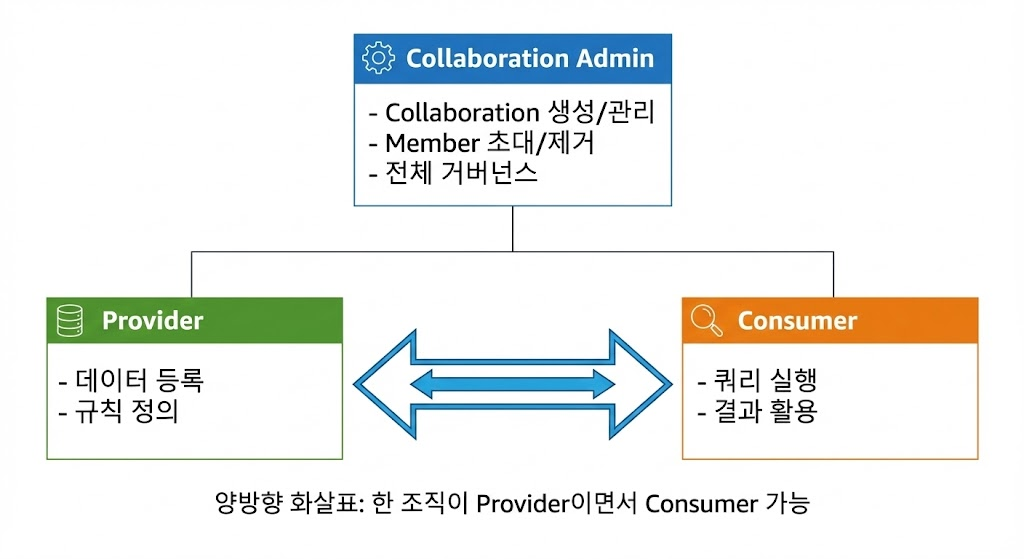
Data Provider는 자신의 데이터를 Collaboration에 등록합니다. Analysis Rules를 정의하여 어떤 쿼리를 허용할지 제어합니다. 쿼리 로그를 확인합니다. 언제든지 공유를 중단할 수 있습니다. 데이터 품질을 유지하고, 적절한 프라이버시 규칙을 설정하며, 규제를 준수할 책임이 있습니다.
Data Consumer는 Collaboration에 참여하여 쿼리를 실행합니다. Provider가 정의한 규칙 내에서만 분석할 수 있습니다. 결과를 다운로드합니다. 자신의 쿼리 히스토리를 확인합니다. 일반적으로 쿼리 비용을 부담합니다. 결과 데이터를 적절하게 사용하고, 규제를 준수할 책임이 있습니다.
Collaboration Admin은 Collaboration을 생성하고 설정합니다. Member를 초대하고 제거합니다. 전체 쿼리 로그를 확인합니다. 비용 배분 정책을 설정합니다. 협업 목적과 범위를 정의하고, 분쟁을 조정하며, 전체 거버넌스를 책임집니다.
하나의 조직이 여러 역할을 동시에 수행할 수 있습니다. 두 리테일 기업이 서로의 고객 데이터를 교차 분석하는 경우, 각자가 Provider이면서 동시에 Consumer입니다.
리테일 생태계 예시를 보겠습니다. 쇼핑몰에 Brand A, Brand B, Mall Operator 세 조직이 참여합니다. Brand A는 Provider이자 Consumer입니다. 자신의 고객 데이터와 구매 데이터를 제공하고, 다른 브랜드 및 몰 데이터를 분석합니다. Brand B도 마찬가지입니다. Mall Operator는 주로 Consumer이지만 트래픽과 이벤트 데이터를 제공하기도 합니다. Admin 역할도 수행합니다. Brand A와 Brand B는 고객 중복을 분석합니다. Mall Operator는 전체 트래픽 대비 구매 전환율을 분석합니다. Brand A는 몰 이벤트가 자사 매출에 미친 영향을 분석합니다.
모든 활동은 투명합니다. 감사 로그에 모든 것이 기록됩니다. 누가 언제 어떤 쿼리를 실행했는지, 얼마나 많은 데이터를 스캔했는지, 어떤 결과를 가져갔는지, 어떤 프라이버시 체크가 적용되었는지. 모든 참여자가 자신과 관련된 로그를 확인할 수 있습니다. Provider는 자신의 데이터에 대한 모든 접근을 봅니다. Consumer는 자신의 쿼리 히스토리를 봅니다. Admin은 전체 활동 현황을 봅니다.
중요한 결정은 상호 합의를 통해 이루어집니다. Analysis Rule을 설정할 때, Provider가 초안을 제안합니다. “최소 1000명 이상, 연령대와 지역 컬럼만 허용, 이메일 해시로 조인 가능.” Consumer가 검토하고 피드백합니다. “1000명은 너무 높습니다. 우리 캠페인은 보통 500-800명 규모입니다. 100명으로 낮춰주시면 좋겠습니다.” 협상이 시작됩니다. Provider는 “100명은 너무 낮습니다. 재식별 위험이 있습니다.” Consumer는 “그럼 Differential Privacy를 추가하면 어떨까요?” Provider는 “좋습니다. 그럼 threshold 200 + DP로 합의하겠습니다.” 최종 합의안이 만들어집니다. “최소 200명, 연령대/지역/구매카테고리 컬럼 허용, 이메일 해시로 조인, Differential Privacy epsilon 2.0.” 양측이 승인하면 규칙이 활성화됩니다.
Privacy-by-Design 기반 설계
Clean Rooms은 사후적인 보안 조치가 아니라, 설계 단계부터 프라이버시를 고려합니다. Privacy-by-Design의 7가지 원칙을 모두 구현합니다.
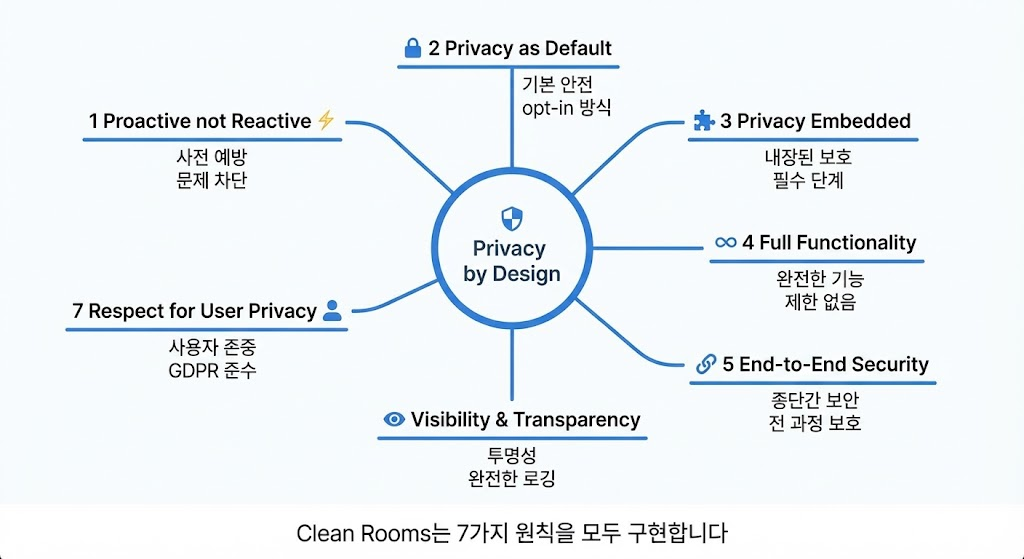
첫째, Proactive not Reactive입니다. 사전 예방입니다. 전통적 방식은 데이터를 공유하고, 문제가 발생하면, 사후 대응합니다. Clean Rooms 방식은 프라이버시 규칙을 먼저 정의하고, 규칙 위반 쿼리는 실행 전에 차단하며, 문제 발생 자체를 방지합니다.
둘째, Privacy as Default입니다. 기본 설정이 안전합니다. 테이블을 등록하면 기본적으로 개별 레코드 접근이 불가능합니다. 집계만 허용됩니다. 최소 임계값이 설정됩니다. 감사 로깅이 활성화됩니다. 민감 컬럼은 차단됩니다. 사용자가 명시적으로 완화해야 합니다. opt-in 방식입니다. 기본이 안전한 상태입니다.
셋째, Privacy Embedded입니다. 프라이버시가 내장되어 있습니다. 쿼리 실행 파이프라인을 보겠습니다. 쿼리 제출, 문법 검증, 프라이버시 규칙 체크(자동 적용), 쿼리 실행, 결과 프라이버시 체크(자동 적용), 결과 전달. 프라이버시 체크는 선택사항이 아닌 필수 단계입니다. 우회할 수 없습니다.
넷째, Full Functionality입니다. 완전한 기능성입니다. 프라이버시 보호가 기능 제한을 의미하지 않습니다. Clean Rooms에서 복잡한 JOIN, 윈도우 함수, 서브쿼리, CTE, 집계 함수, 통계 함수, 날짜/시간 함수, 문자열 함수를 모두 사용할 수 있습니다. 단, 모든 기능이 프라이버시 규칙 내에서 작동합니다.
다섯째, End-to-End Security입니다. 종단 간 보안입니다. 저장 데이터는 S3 암호화로 보호됩니다. 원본 데이터는 제공자의 계정에만 존재합니다. 전송 데이터는 TLS 1.2+ 암호화로 보호됩니다. VPC Endpoint를 사용할 수 있습니다. 사용 중 데이터는 Athena 쿼리 실행 시 임시 데이터도 암호화됩니다. 메모리 내 데이터도 보호됩니다. 쿼리 결과도 암호화하여 S3에 저장됩니다. 접근 권한을 엄격히 제어합니다. 감사 로그도 CloudTrail로 기록되며 암호화 및 무결성이 보장됩니다.
여섯째, Visibility and Transparency입니다. 가시성과 투명성입니다. 모든 참여자가 필요한 정보를 볼 수 있습니다. Provider는 누가 내 데이터에 접근했는지, 어떤 쿼리를 실행했는지, 얼마나 많은 데이터를 스캔했는지, 어떤 결과를 가져갔는지 봅니다. Consumer는 어떤 데이터를 사용할 수 있는지, 어떤 쿼리가 허용되는지, 내 쿼리가 왜 실패했는지, 비용이 얼마나 발생했는지 봅니다. Admin은 전체 활동 현황, 비용 분석, 이상 패턴을 봅니다.
일곱째, Respect for User Privacy입니다. 사용자 프라이버시 존중입니다. 최종 사용자, 즉 데이터 주체의 관점에서 생각합니다. 전통적 데이터 공유에서는 “내 데이터가 어디로 갔는지, 누가 보는지 모릅니다. 삭제 요청해도 이미 복제된 데이터는 어떻게 되는지 모릅니다.” Clean Rooms 사용 시에는 “내 데이터는 원래 회사의 서버에만 존재합니다. 다른 회사는 나를 식별할 수 없는 집계 결과만 봅니다. 원래 회사가 공유를 중단하면 즉시 접근이 불가능합니다.” GDPR Article 25 Data Protection by Design을 준수합니다. 최소 데이터 수집, 목적 제한, 저장 기간 제한, 무결성 및 기밀성을 보장합니다.
핵심은 사후 보안이 아닌 설계 단계부터의 프라이버시가 규제 승인을 빠르게 한다는 것입니다.
4. AWS Clean Rooms 소개
핵심 구성 요소
AWS Clean Rooms는 네 가지 핵심 구성 요소로 이루어져 있습니다. Collaboration, Membership, Tables, Analysis Rules입니다.
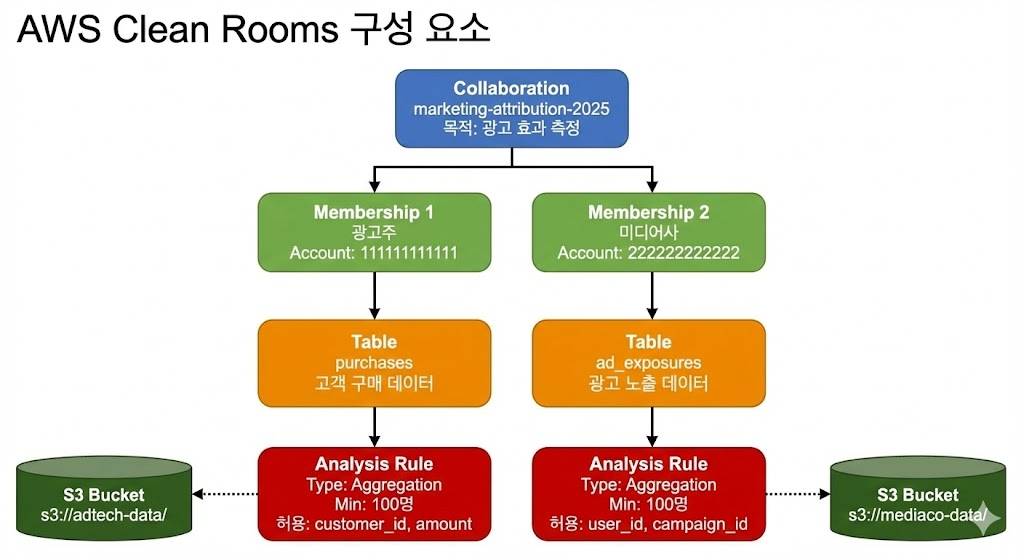
- Collaboration은 여러 조직이 함께 작업하는 논리적 공간입니다. 협업의 목적, 참여자, 규칙을 정의합니다. 하나의 Collaboration에 여러 Member가 참여합니다. 예를 들어, “marketing-attribution-2025″라는 Collaboration을 만들 수 있습니다. 목적은 “광고 효과 측정을 위한 광고주-미디어사 협업”입니다. 참여자는 광고주와 미디어사입니다. 규칙은 “집계 쿼리만 허용, 최소 100명 이상”입니다.
- Membership은 각 조직의 Collaboration 참여 단위입니다. AWS 계정 단위로 생성됩니다. 각 Member는 자신의 데이터와 권한을 독립적으로 관리합니다. 광고주는 자신의 AWS 계정으로 Membership을 만들고, 미디어사도 자신의 AWS 계정으로 Membership을 만듭니다. 각자 독립적으로 데이터를 등록하고, 규칙을 설정하고, 쿼리를 실행합니다.
- Tables는 Glue Data Catalog에 등록된 테이블을 참조합니다. 실제 데이터는 S3에 저장되어 있으며 이동하지 않습니다. 각 Member가 자신의 테이블을 Collaboration에 등록합니다. 광고주는 “purchases” 테이블을 등록합니다. 미디어사는 “ad_exposures” 테이블을 등록합니다. 테이블 스키마는 공유되지만, 실제 데이터는 각자의 S3에 그대로 있습니다.
- Analysis Rules는 테이블에 대해 허용되는 쿼리 패턴을 정의합니다. Aggregation, List, Custom 세 가지 유형이 있습니다. 최소 집계 단위, 허용 컬럼, 출력 제약 등을 설정합니다. 광고주는 “purchases” 테이블에 Aggregation Rule을 설정합니다. “최소 100명 이상, amount는 SUM 가능, customer_id는 COUNT_DISTINCT 가능, customer_id로 조인 가능, channel과 product_id로 GROUP BY 가능.”
Athena 기반 쿼리 실행 구조
AWS Clean Rooms는 내부적으로 Amazon Athena를 활용합니다. Athena는 S3의 데이터를 직접 쿼리할 수 있는 서버리스 쿼리 엔진입니다.
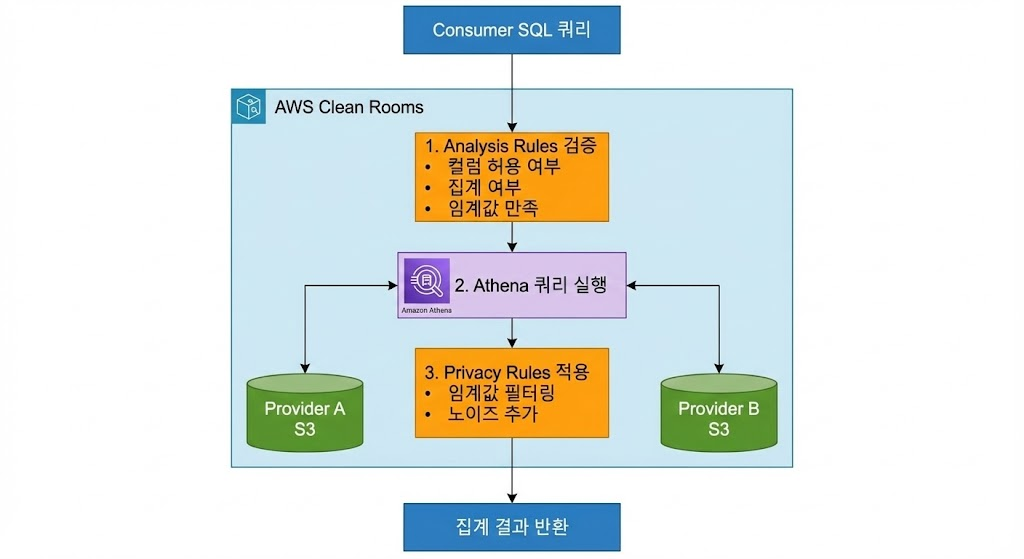
쿼리 실행 흐름을 보겠습니다. Consumer가 SQL 쿼리를 작성합니다. "SELECT campaign_id, COUNT(DISTINCT customer_id), SUM(amount) FROM purchases JOIN ad_exposures ON customer_id = user_id GROUP BY campaign_id HAVING COUNT(DISTINCT customer_id) >= 100." Clean Rooms가 Analysis Rules를 검증합니다. customer_id 컬럼 사용이 허용되는가? 예, join_columns에 포함되어 있습니다. amount 컬럼에 SUM 사용이 허용되는가? 예, aggregate_columns에 포함되어 있습니다. GROUP BY에 campaign_id 사용이 허용되는가? 예, dimension_columns에 포함되어 있습니다. 최소 임계값을 만족하는가? 예, HAVING 절에 100 이상 조건이 있습니다.
검증을 통과하면 Athena가 각 Member의 S3 데이터를 직접 읽어 쿼리를 실행합니다. 광고주의 S3에서 purchases 데이터를 읽습니다. 미디어사의 S3에서 ad_exposures 데이터를 읽습니다. 두 데이터를 조인하고 집계합니다. 결과에 Privacy Rules를 적용합니다. 100명 미만인 그룹이 있는가? 있다면 제거합니다. Differential Privacy가 설정되어 있는가? 있다면 노이즈를 추가합니다. 최종 결과만 Consumer에게 반환합니다.
이 구조의 장점은 명확합니다.
- 확장성
- Athena의 서버리스 아키텍처로 대용량 데이터를 처리할 수 있습니다. 수 테라바이트, 수 페타바이트 데이터도 문제없습니다.
- 비용 효율성
- 스캔한 데이터 양만큼만 과금됩니다. 사용하지 않으면 비용이 발생하지 않습니다.
- 표준 SQL
- 별도의 학습 없이 기존 SQL 지식을 활용할 수 있습니다. ANSI SQL을 지원합니다.
Zero-Copy Data Model
AWS Clean Rooms의 가장 큰 특징은 Zero-Copy 모델입니다. 데이터를 복사하지 않습니다.
데이터는 각 조직의 S3 버킷에 그대로 유지됩니다. 광고주의 데이터는 광고주의 S3에 있습니다. 미디어사의 데이터는 미디어사의 S3에 있습니다. Glue Catalog를 통해 메타데이터만 공유됩니다. 테이블 이름, 컬럼 이름, 데이터 타입, 파티션 정보만 공유됩니다. 실제 데이터는 공유되지 않습니다. 쿼리 실행 시 Athena가 원본 데이터를 직접 읽습니다. 중간 복사본이 생성되지 않습니다. 보안 리스크가 최소화됩니다.
이것이 왜 중요할까요?
- 데이터 통제권을 유지합니다.
- 제공자는 언제든지 공유를 중단할 수 있습니다. S3 버킷의 권한을 변경하거나, Collaboration에서 테이블을 제거하면 됩니다.
- 즉시 효력이 발생하므로 데이터 최신성을 보장합니다.
- 제공자가 데이터를 업데이트하면 자동으로 반영됩니다. Consumer는 항상 최신 데이터를 분석합니다. 별도의 동기화 작업이 필요 없습니다.
- 저장 비용을 절감합니다.
- 데이터를 복제하지 않으므로 추가 저장 비용이 발생하지 않습니다.
- 규제 준수가 쉽습니다.
- 데이터가 원래 위치를 벗어나지 않으므로, 데이터 거주 요구사항을 쉽게 만족합니다. 유럽 데이터는 유럽 리전에, 한국 데이터는 한국 리전에 그대로 유지됩니다.
5. re:Invent 2025 핵심 업데이트
AWS re:Invent 2025에서 발표된 Clean Rooms의 새로운 기능들은 단순한 개선이 아니라, 데이터 협업의 가능성을 한 단계 더 확장하는 혁신입니다.
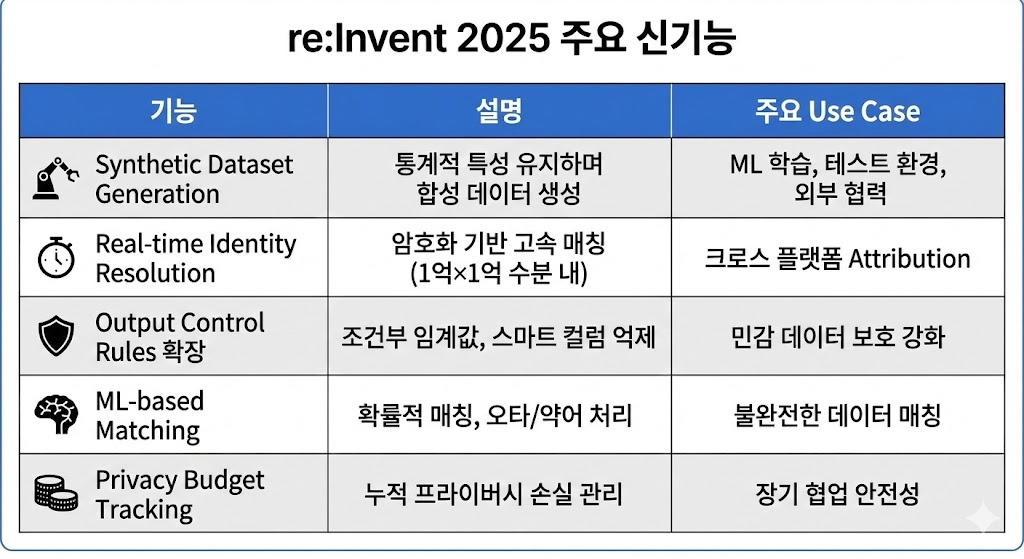
Synthetic Dataset Generation
가장 주목받은 기능은 Synthetic Dataset Generation입니다. 실제 데이터의 통계적 특성을 유지하면서 개인정보를 완전히 제거한 합성 데이터를 생성합니다.
작동 원리를 이해해봅시다. 원본 데이터가 있습니다. 100만 명의 고객 데이터입니다. 연령, 지역, 구매 금액, 구매 빈도 등의 정보가 있습니다. Clean Rooms는 이 데이터의 통계적 특성을 학습합니다. 연령 분포, 지역별 비율, 구매 금액의 평균과 분산, 연령과 구매 금액의 상관관계 등을 학습합니다. 그리고 이 특성을 가진 새로운 데이터를 생성합니다. 생성된 데이터는 원본과 통계적으로 유사하지만, 실제 개인과는 1:1로 매칭되지 않습니다.
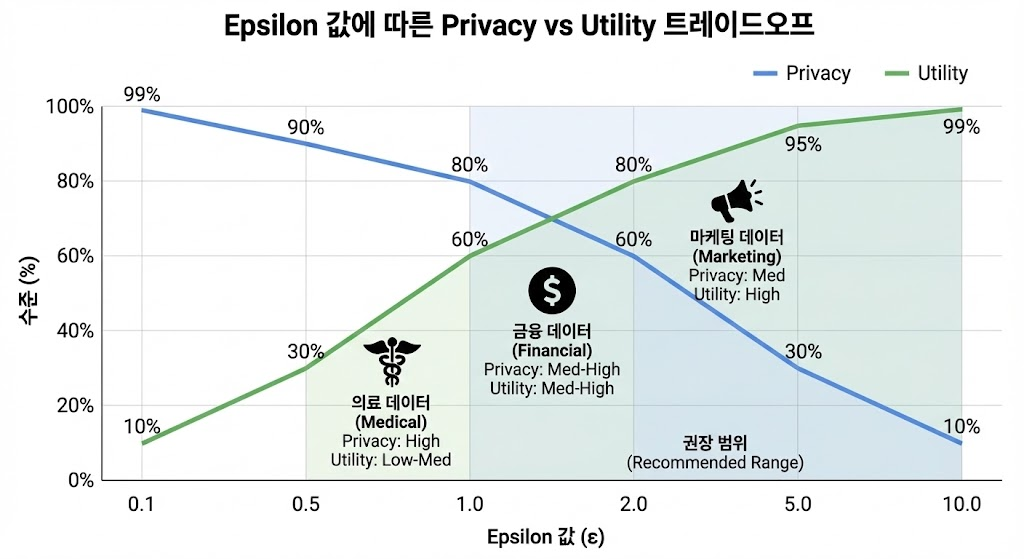
Differential Privacy 기반입니다. 수학적으로 증명 가능한 프라이버시 보장입니다. 원본 데이터의 개별 레코드를 역추적하는 것이 불가능합니다. epsilon 파라미터로 프라이버시 강도를 조절합니다. epsilon이 낮을수록 프라이버시가 강하지만, 데이터 유용성은 다소 감소합니다. epsilon이 높을수록 데이터 유용성이 높지만, 프라이버시는 다소 약해집니다. 일반적으로 epsilon 1.0-10.0 범위를 사용합니다.
활용 사례는 다양합니다.
- ML 학습에 활용합니다. 합성 데이터로 모델을 Pre-training하고, 실제 데이터로 Fine-tuning합니다. 개발자가 프로덕션 데이터에 접근하지 않고도 모델을 개발할 수 있습니다.
- 테스트 환경 구축에 활용합니다. 프로덕션 데이터의 특성을 반영한 안전한 테스트 데이터를 생성합니다. 개인정보 유출 걱정 없이 QA와 성능 테스트를 수행할 수 있습니다.
- 외부 협력에 활용합니다. 합성 데이터는 규제 제약 없이 외부에 공유할 수 있습니다. 파트너사, 연구기관, 컨설팅 업체와 안전하게 협업할 수 있습니다.
Real-time Identity Resolution 개선
서로 다른 조직의 고객 데이터를 매칭하는 기능이 대폭 강화되었습니다.
- 암호화 기반 매칭이 개선되었습니다. 이메일, 전화번호 등을 해시화하여 매칭합니다. 양측이 동일한 해시 알고리즘을 사용하면, 동일한 이메일은 동일한 해시값을 가집니다. 원본 이메일을 공유하지 않고도 매칭할 수 있습니다. SHA-256, HMAC 등 다양한 알고리즘을 지원합니다. Salt 값을 사용하여 보안을 강화할 수 있습니다.
- 확률적 매칭이 추가되었습니다. 이름, 주소 등 불완전한 정보로도 매칭할 수 있습니다. “홍길동, 서울시 강남구”와 “Hong Gildong, Gangnam-gu Seoul”을 동일 인물로 매칭합니다. 오타, 약어, 순서 변경 등을 처리합니다. 매칭 신뢰도 점수를 제공합니다. 90% 이상 신뢰도만 사용하는 등 임계값을 설정할 수 있습니다.
- 성능이 대폭 향상되었습니다. 수억 건의 레코드도 실시간으로 처리할 수 있습니다. 1억 건 x 1억 건 매칭을 수 분 내에 완료합니다. 병렬 처리와 최적화된 알고리즘을 사용합니다. 비용도 합리적입니다. TB당 15달러로 대규모 매칭이 가능합니다.
Output Control Rules 확장
분석 결과의 프라이버시 보호 기능이 더욱 정교해졌습니다.
- Aggregation Threshold가 유연해졌습니다. 단순히 최소 인원수만 설정하는 것이 아니라, 조건부 임계값을 설정할 수 있습니다. “일반 쿼리는 100명 이상, 민감 컬럼 포함 시 500명 이상, 특정 지역 데이터는 1000명 이상.” 컬럼별, 조건별로 다른 임계값을 적용할 수 있습니다.
- Noise Injection이 고도화되었습니다. Differential Privacy 기반 노이즈 추가가 더 정교해졌습니다. Laplace noise, Gaussian noise 등 다양한 노이즈 분포를 선택할 수 있습니다. 쿼리 복잡도에 따라 노이즈 양을 자동 조절합니다. Privacy Budget을 추적하여 누적 프라이버시 손실을 관리합니다.
- Column Suppression이 스마트해졌습니다. 특정 조건에서 민감 컬럼을 자동으로 제거합니다. “그룹 크기가 50명 미만이면 이메일 도메인 컬럼 제거.” “특정 지역 데이터는 상세 주소 컬럼 제거.” 규칙 기반으로 자동 적용됩니다.
- Row Filtering이 추가되었습니다. 특정 조건의 행만 쿼리 가능하도록 제한합니다. “최근 1년 데이터만 쿼리 가능.” “동의한 고객 데이터만 쿼리 가능.” “특정 지역 데이터만 쿼리 가능.” Provider가 세밀하게 제어할 수 있습니다.
6. 마무리:데이터 공유의 새로운 기본 옵션
“위험 vs 가치” 균형의 해결
기존에는 데이터 공유를 결정할 때 이분법적 선택을 해야 했습니다. 공유한다면 높은 분석 가치를 얻지만, 보안 리스크와 규제 위반 가능성을 감수해야 했습니다. 공유하지 않는다면 안전하지만, 협업 기회를 상실하고 비즈니스 가치가 제한되었습니다.
AWS Clean Rooms는 이 딜레마를 해결하는 제3의 선택지를 제공합니다. 데이터는 공유하지 않으면서도 협업이 가능합니다. 프라이버시는 보호하면서도 분석 가치를 확보합니다. 규제 준수와 비즈니스 혁신을 동시에 달성합니다.
Mobilewalla APAC Sales 부문 VP는 이렇게 말했습니다.
“디지털 대부업체와의 파트너십에서 기본적인 것은 데이터 협업입니다. 당사는 가치 시연의 초기 단계부터 제품 업그레이드 및 유지 관리의 후기 단계에 이르기까지 데이터를 중심으로 고객과 긴밀하게 협력합니다. AWS Clean Rooms를 사용하면 안전한 환경에서 고객과 미션 크리티컬 데이터에 대해 협업할 수 있으므로 데이터 협업이 촉진됩니다. 이는 개발 도상국에서 신용에 대한 접근성을 확대하려는 당사의 목표를 뒷받침합니다.”
데이터 협업의 민주화
Clean Rooms는 이전에는 대기업만 구축할 수 있었던 복잡한 데이터 협업 인프라를 서비스 형태로 제공합니다. 수억 원의 초기 투자, 수개월의 개발 기간, 전문 인력이 필요했던 것이 이제는 몇 시간 만에, 클릭 몇 번으로 가능합니다.
중소기업도 파트너와 안전하게 데이터를 협업할 수 있습니다. 스타트업도 대기업과 대등하게 데이터 기반 협업을 제안할 수 있습니다. 새로운 데이터 기반 비즈니스 모델을 실험할 수 있습니다. 데이터 협업이 소수의 특권이 아니라, 모두가 활용할 수 있는 도구가 되었습니다.
Adobe Product Management Senior Director는 이렇게 말했습니다.
“Adobe의 Real-Time CDP Collaboration 제품을 사용하면 고객은 안전한 개인정보 보호 규정 준수 환경에서 새로운 고객을 발견하고 캠페인을 활성화하며 광고 투자 수익률을 측정할 수 있습니다. AWS Clean Rooms를 CDP 기술 스택에 통합함으로써 AWS 고객은 기본 데이터를 공유하거나 복사하지 않고도 Adobe의 Real-Time CDP 및 함께 일하는 다른 회사와 안전하게 협업하여 마케팅 목표를 달성할 수 있습니다.”
– [AWS re:Invent – Clean Rooms 세션]
– [GDPR 공식 사이트]
김용규 Solutions Architect (caca209@gsneotek.com)
최신 댓글